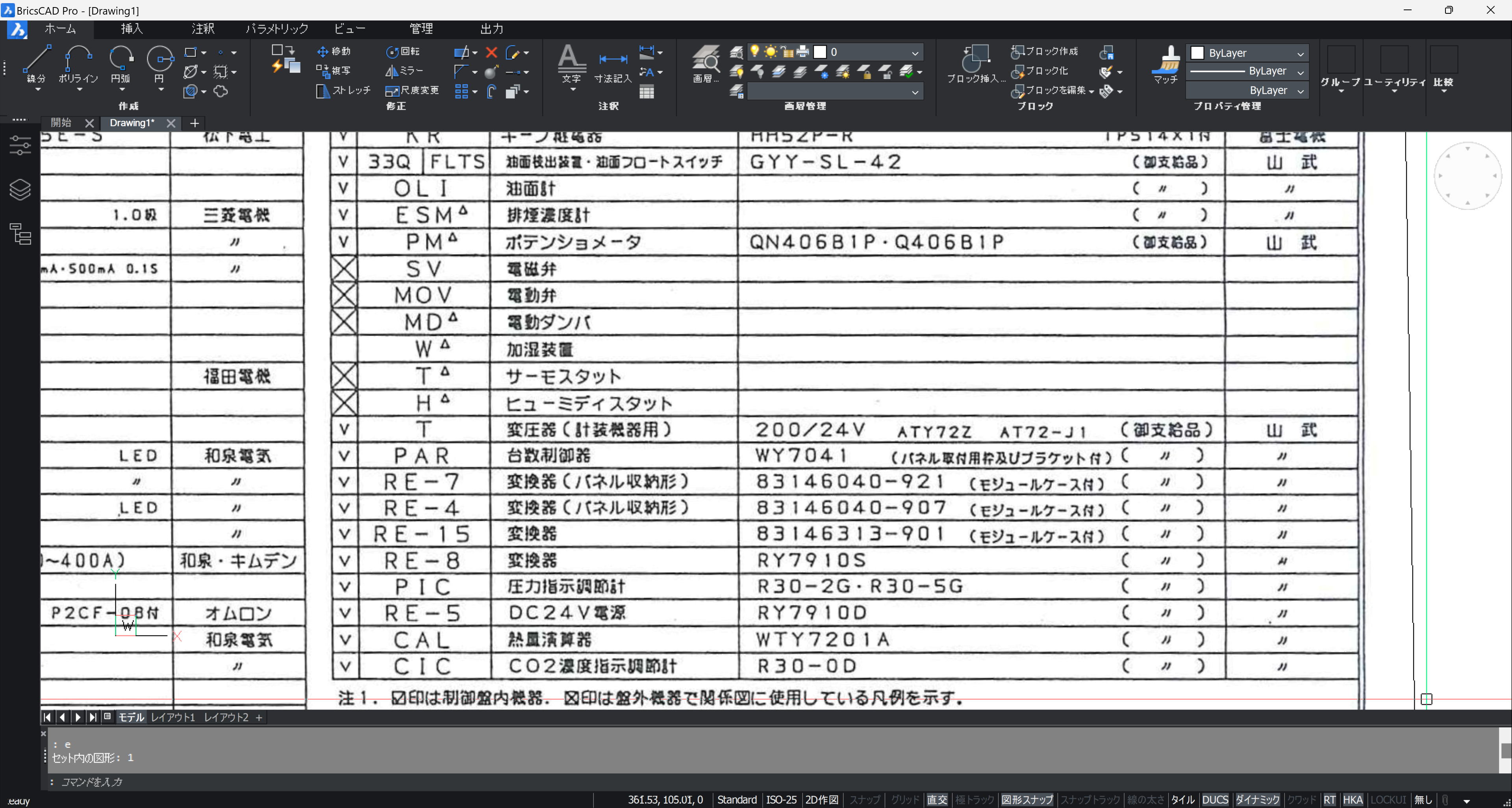
OCR の認識精度をあげるため背景色を白色に変更しています。BricsCAD だと、BKGCOLOR 7[Enter] です。
CADOCR 2 2024/11/24
スキャン図面の OCR 例です。一部、自前のLISP、ツール(青色強調文字)を使っています。
元図面は、紙図面をスキャンした PDF 図面で、図面の傾きは、ROTATE コマンドで修正済です。
OCR の認識精度をあげるため背景色を白色に変更しています。BricsCAD だと、BKGCOLOR 7[Enter] です。
ソースネクスト「瞬間テキスト 3」で、画面上の文字を部分ごとに OCR します。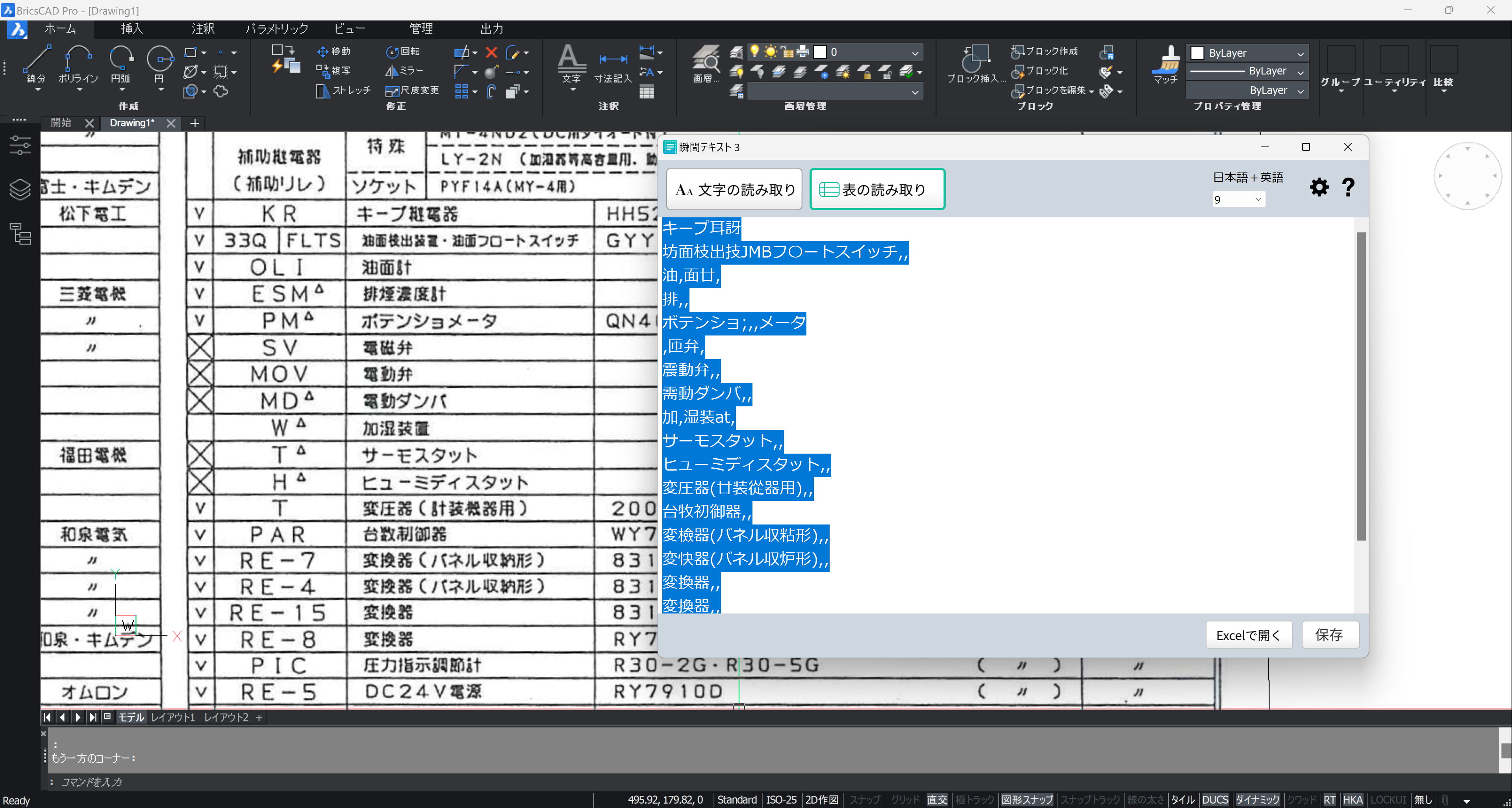
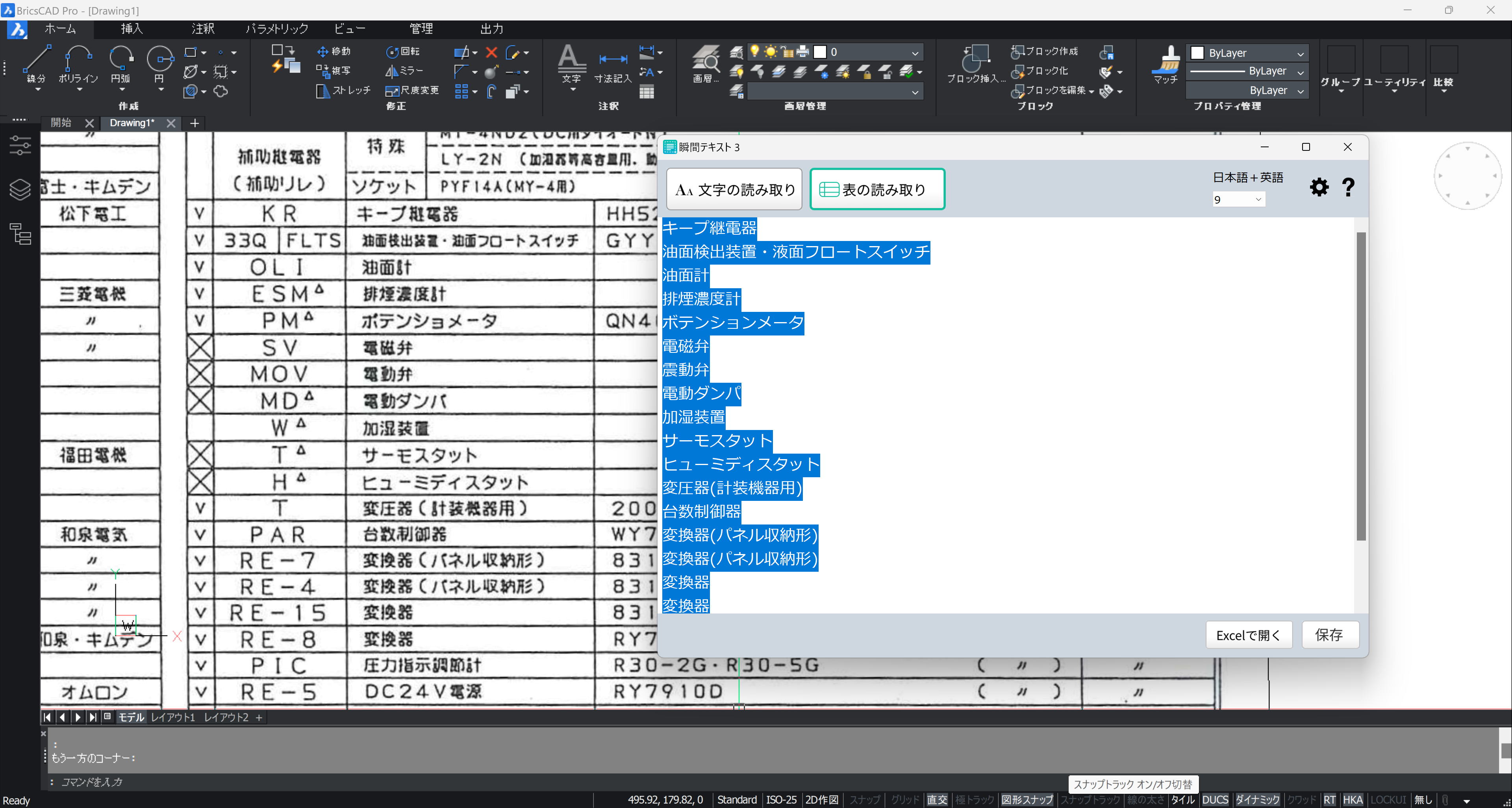
画面の文字と比較しながら OCR 文字を修正します。エクセルでの編集も可能です。
[Ctrl]+[A] ですべてを選択、[Ctrl]+[C] でクリップボードにコピーします。
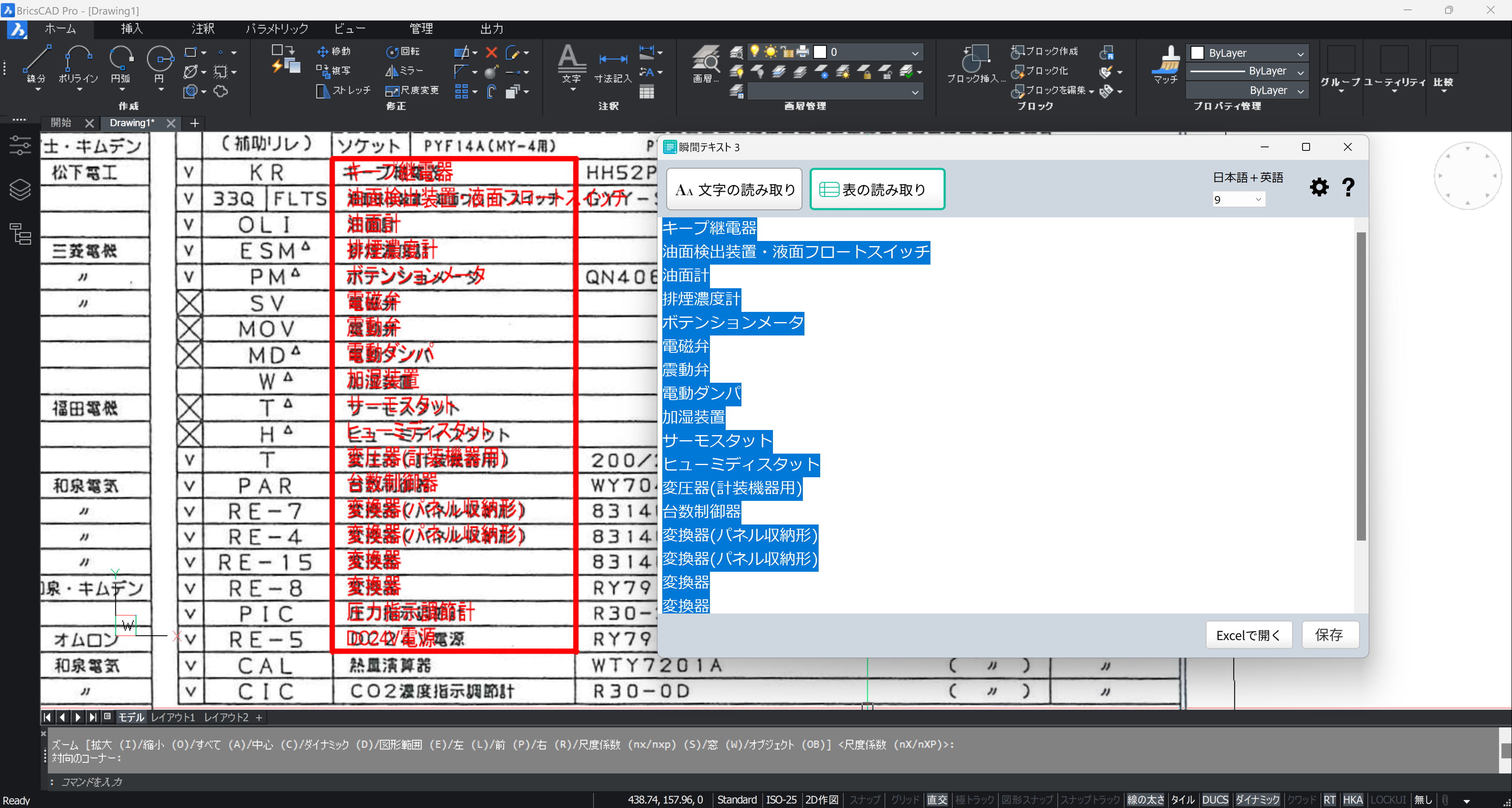
TXRPASTE コマンドで、対象の範囲(下の画像では、赤枠)を指示します。
この大きさとクリップボードの行数から行ピッチを計算し、入力した文字高さで TEXT が作成されます。
これを部分ごとに繰り返します。罫線は、あとでトレースします。
背景色を黒に戻すには、BricsCAD だと、BKGCOLOR 25,25,25[Enter] のように、RGB 値で指定します。0,0,0
が黒色です。
ソースネクスト「いきなりPDF to Data」を使うと、PDF 上の文字(っぽい画像)を OCR できます。
これを PDF と重ね合わせて TEXT を編集するという使い方もできますが、重ね合わせた文字は見にくくて、ストレスになります。
地道に部分ごとに TEXT を作成するのが、間違いが少なくて、ストレスも少ないと思います。
こんな感じ↓です。
元図はすこし傾斜していますが、画面上で OCR するより認識精度は高いです。文字は、1文字ごとの MTEXT になっているので、結合処理が必要になります。
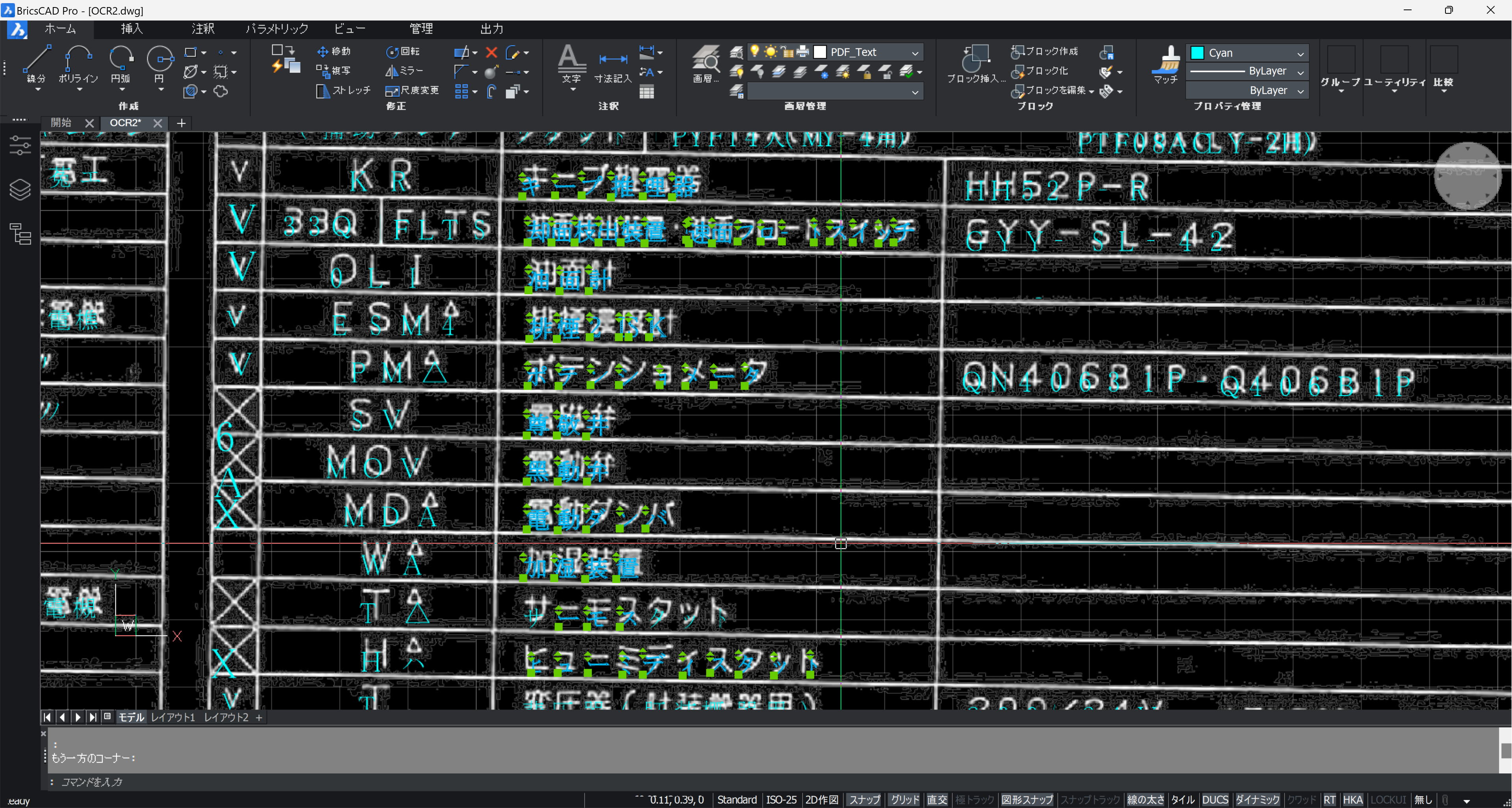
とりあえず TXLCAT で文字を結合した状態↓。
この後、文字を背景の画像と比較しながら、 ED (DDEDIT) コマンドで修正することになりますが、その前に全体の傾きを修正します。
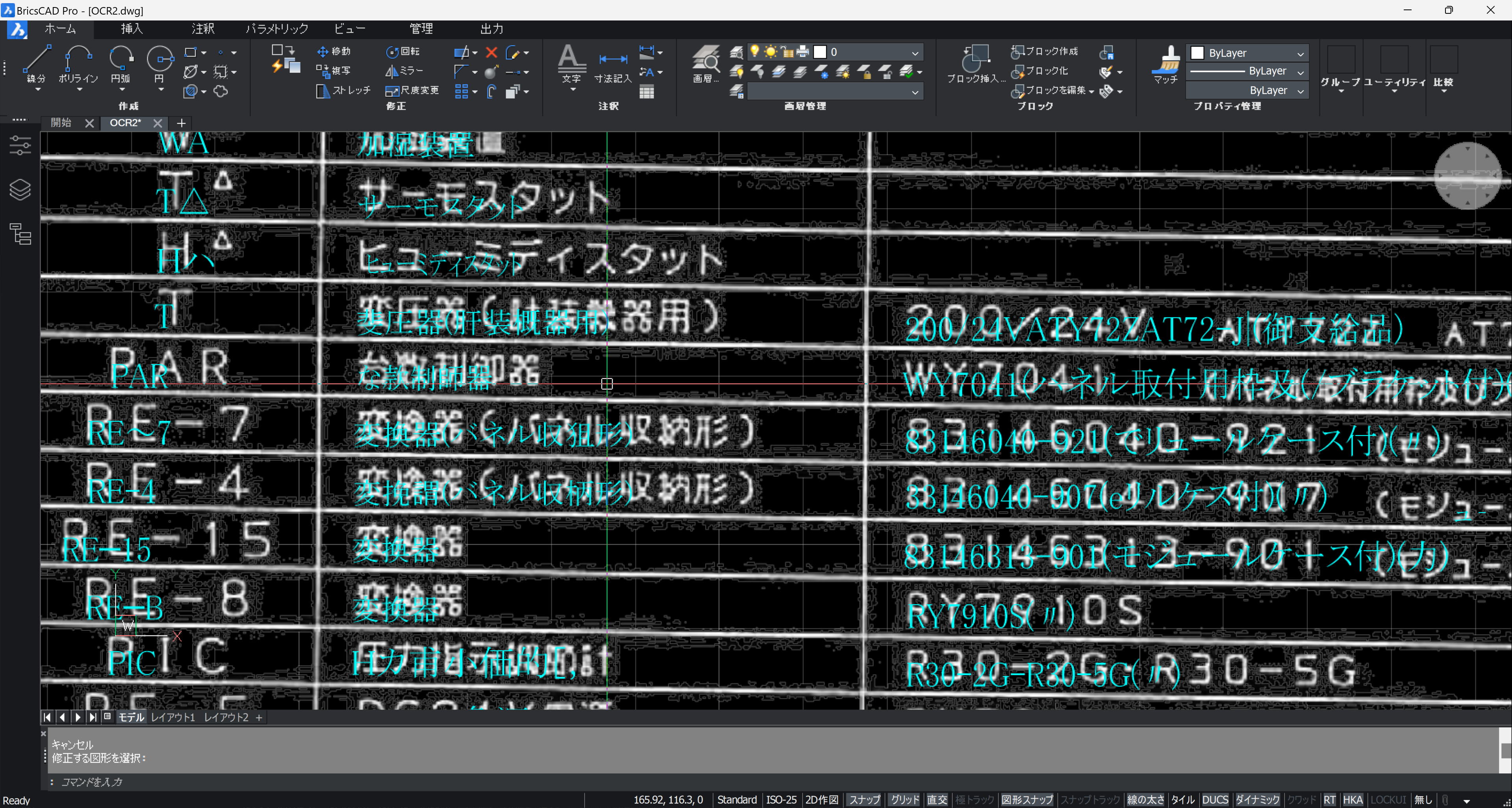
全体の傾きを修正後、文字の回転角度を 0 に戻した状態です。この状態で、罫線を描いていきます。
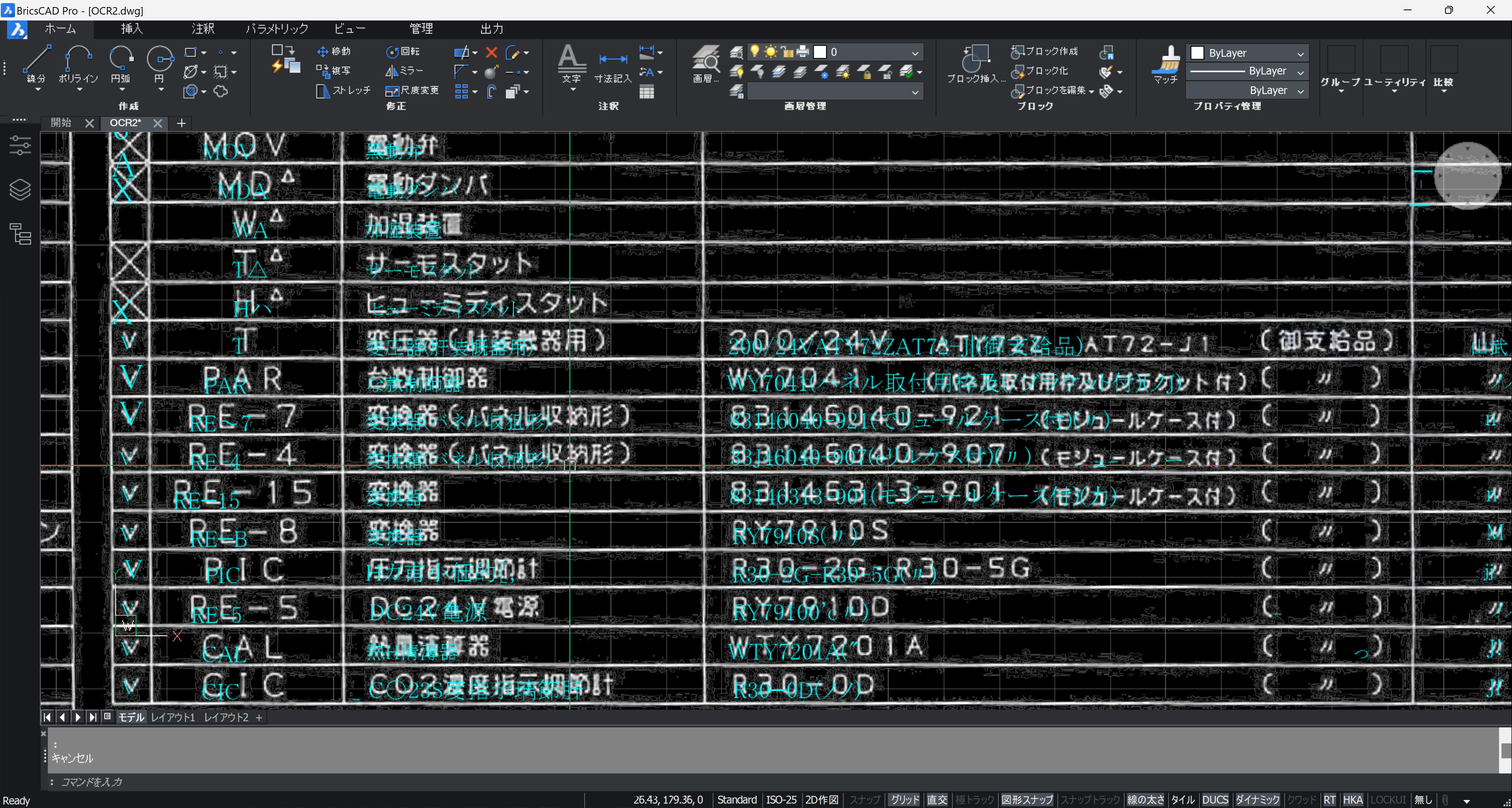
きれいに格子になるところに罫線を描いて、ツール TEXTGRID.exe で格子全体を取得します。
TEXTGRID は、線分(LINE, POLYLINE) で囲われたマス内の1文字 (TEXT) だけを検出します。現バージョンでは、複数の文字があるときは、予め結合しておいて下さい。
一時的に PDF を非表示にすると、スッキリして確認しやすいです。
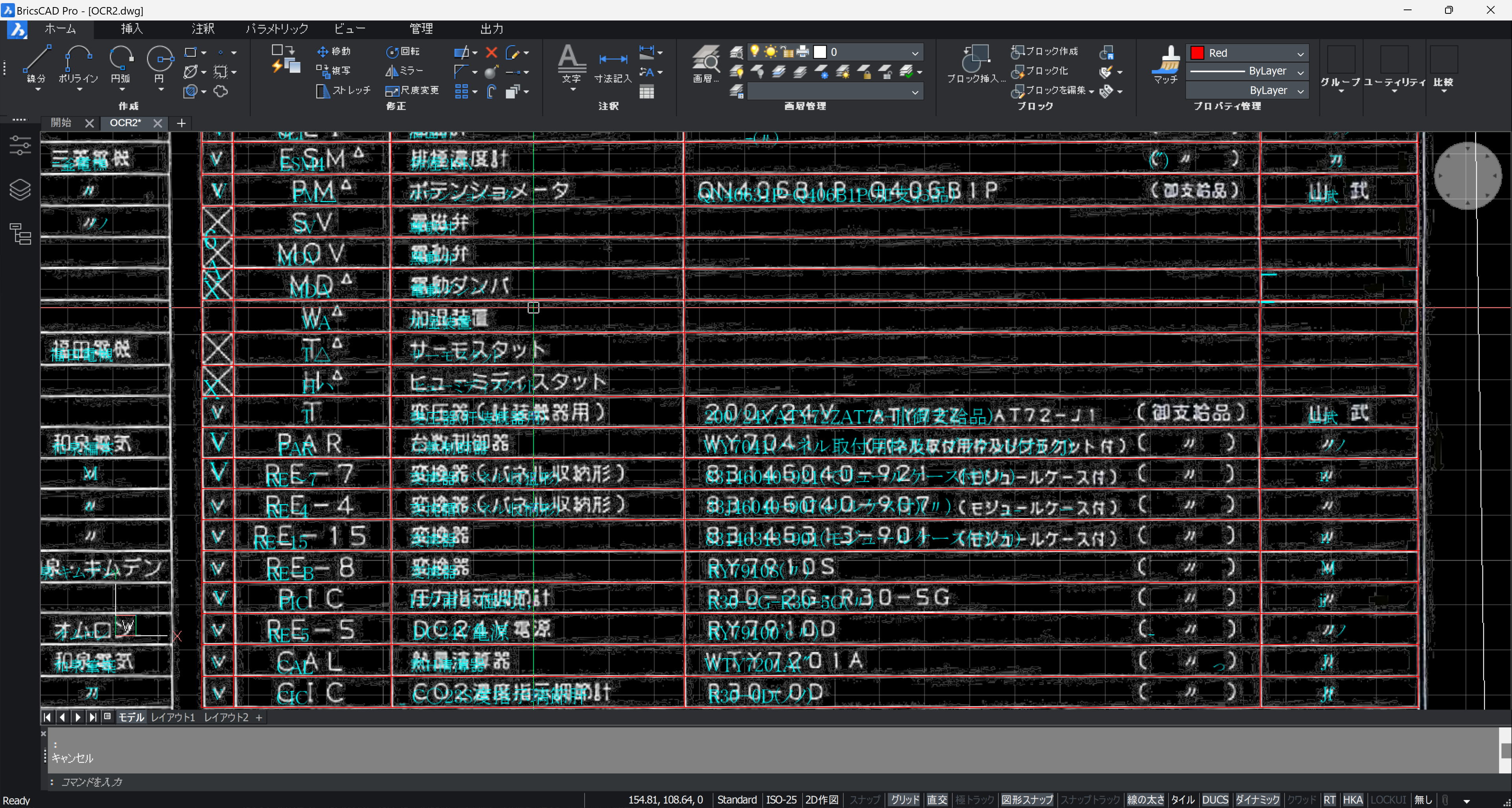
編集対象の TEXT が画面中央に三角で示されるので分かりやすいです。(CAD によって異なります)
長い英数字、日本語を修正します。
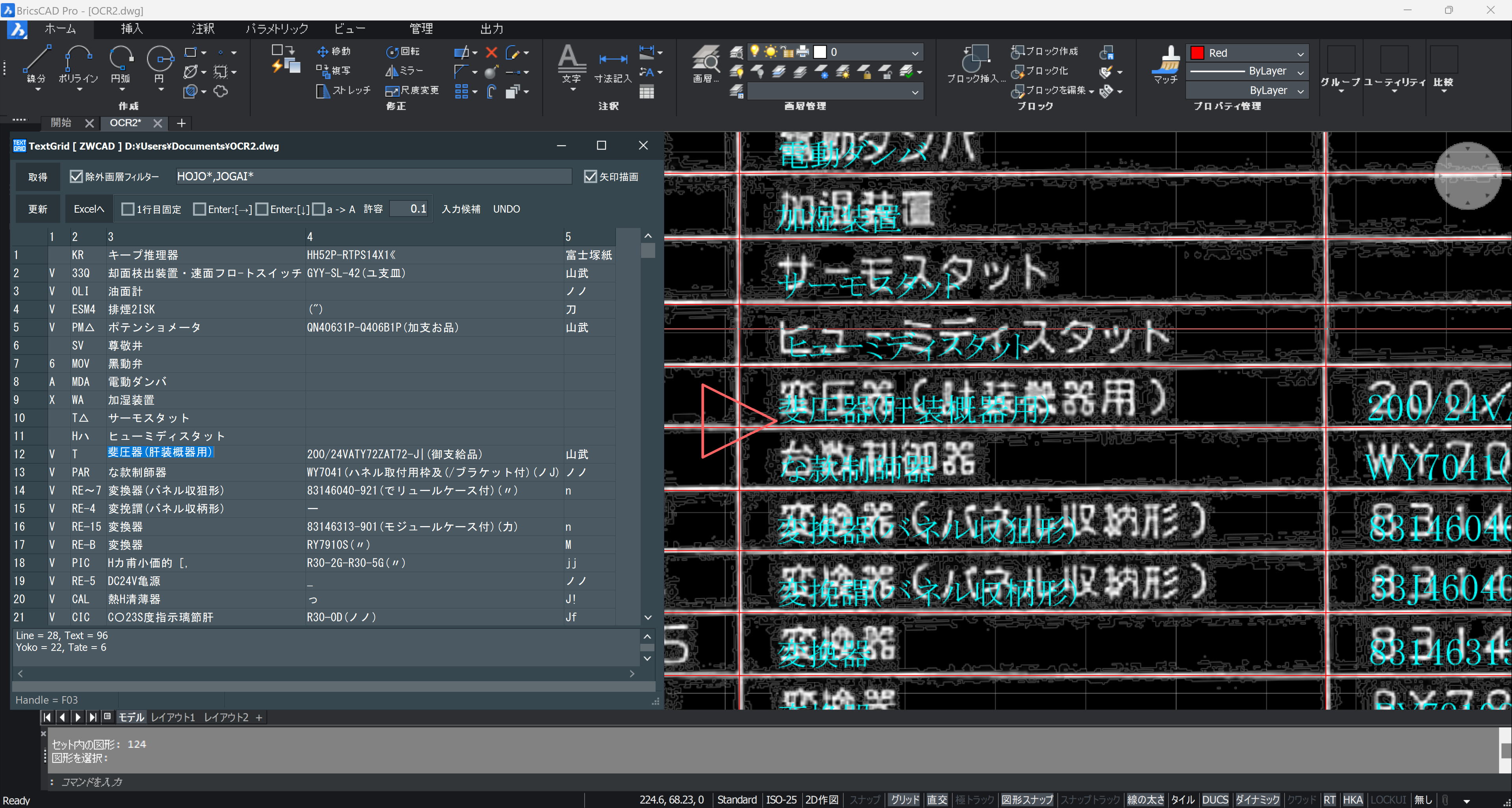
修正後です↓。
"(御支給品)" を結合していますが、右端に独立して並べたいときはダミーの罫線を DEFPOINTS画層に作成します。
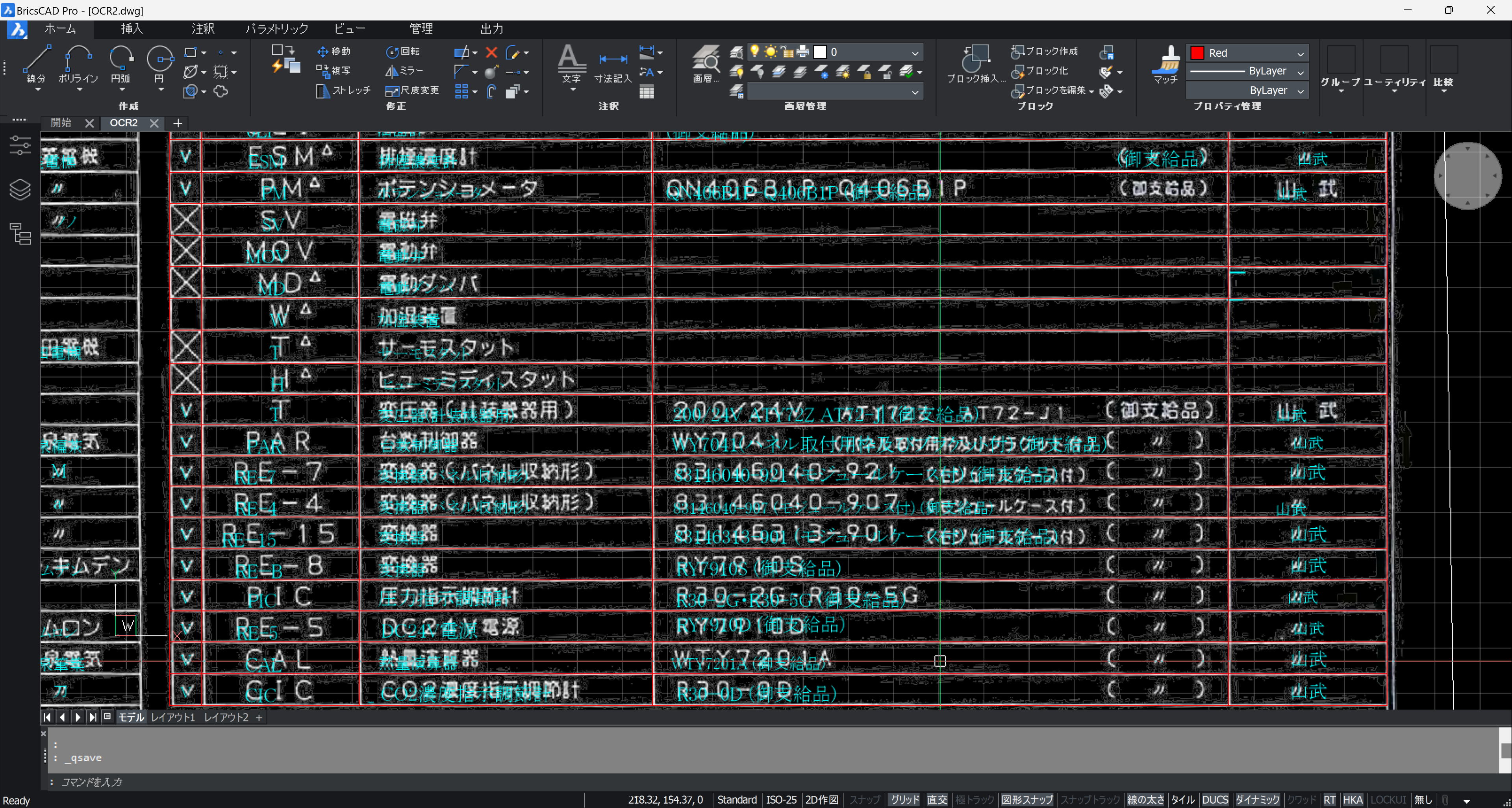
文字の位置を揃えます。対象は線分 (LINE, POLYLINE) で囲まれた1文字列です。
TXGG コマンドで、左、中、右揃えの文字ごとに選択します。文字基点は、ML、 MC、 MR のいずれかに変わります。
罫線の行間は、TXGSPC コマンドで変更できます。
整列後、PDF を非表示にした状態です。
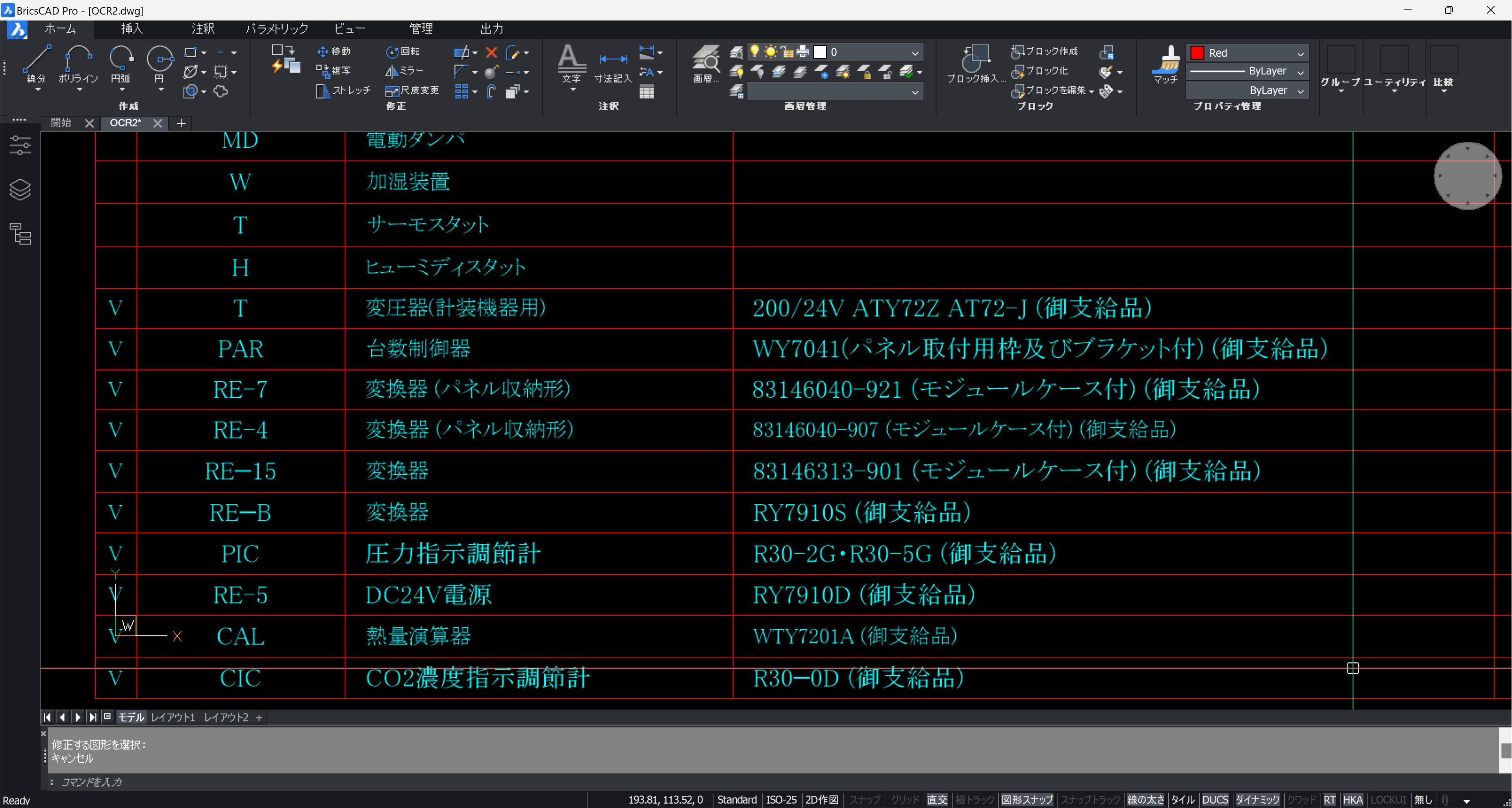
文字の大きさ、幅を変更します。これはプロパティウィンドウから行います。
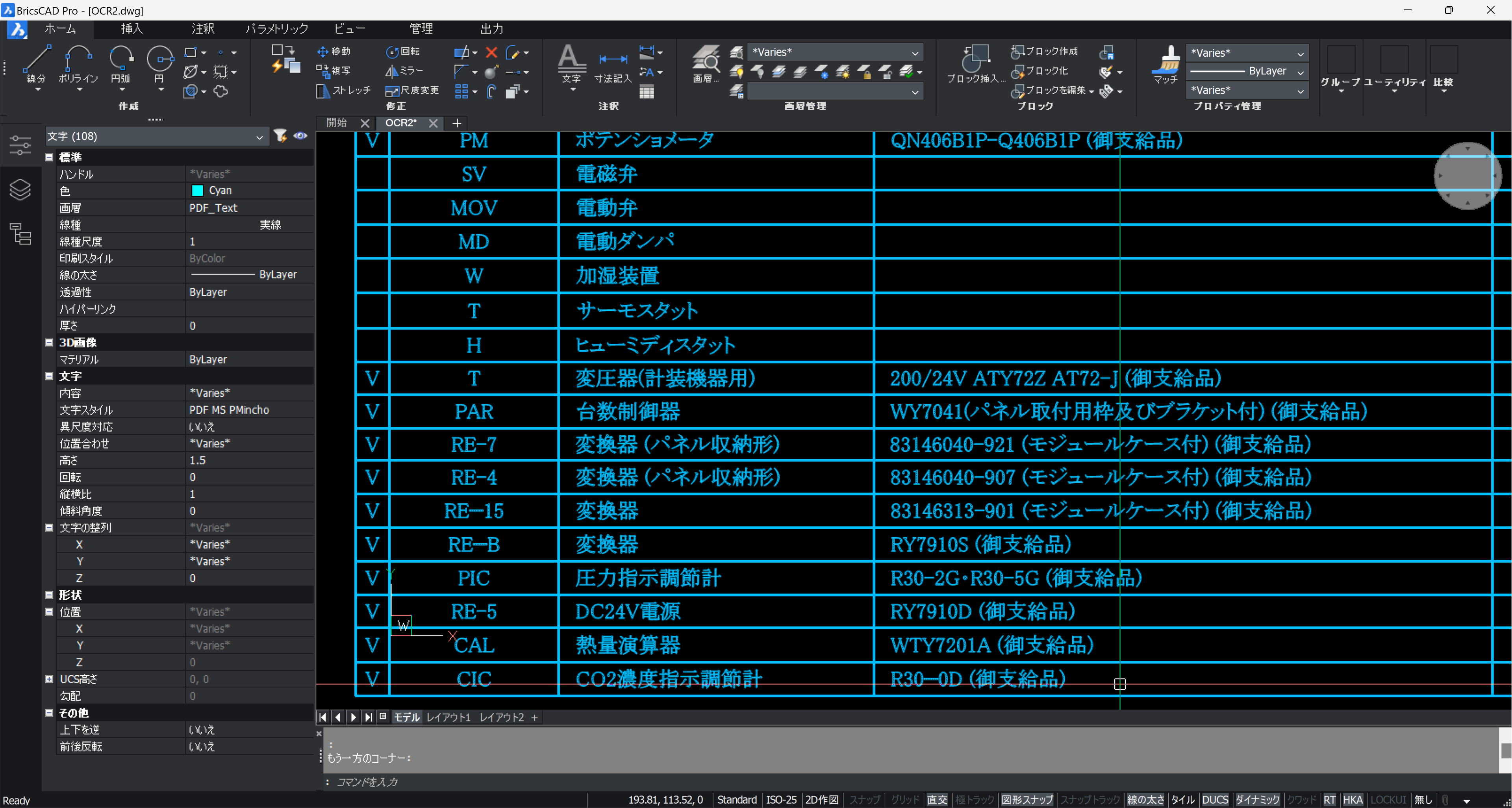
使用したLISP
BTRIMVX232.lsp に収納されています。izawa-web.com/zip/btrimvx232_20241124.zip
・TXLCAT : 複数行の分断文字を結合
・TXGG : 選択した文字の周囲4方向にある LINE, POLYLINE の枠内に位置を調整
・TXGSPC : LINE, POLYLINE で作成された格子の行間、列幅を変更
PDFAID.ZIP の同梱 LISP に収納されています。izawa-web.com/pdfaid/pdfaid1.html
・TXRPASTE : クリップボードの文字を矩形範囲に作成
使用したツール
izawa-web.com/TextGrid/TextGrid2023.html
・TEXTGRID.exe : LINE, POLYLINE で作成された格子内の文字を一括で編集
2024/11/24
f.izawa