と言っても、高価な OCR ではなくて、ソースネクスト「いきなり PDF to Data」を使います。
タイトルどおり CAD (に限らず画面)上の文字を OCR するときは、ソースネクスト「瞬間テキスト 3」を使うとクリップボードにコピーできます。
元の PDF は、汎用 CAD から PDF として印刷された図面です。
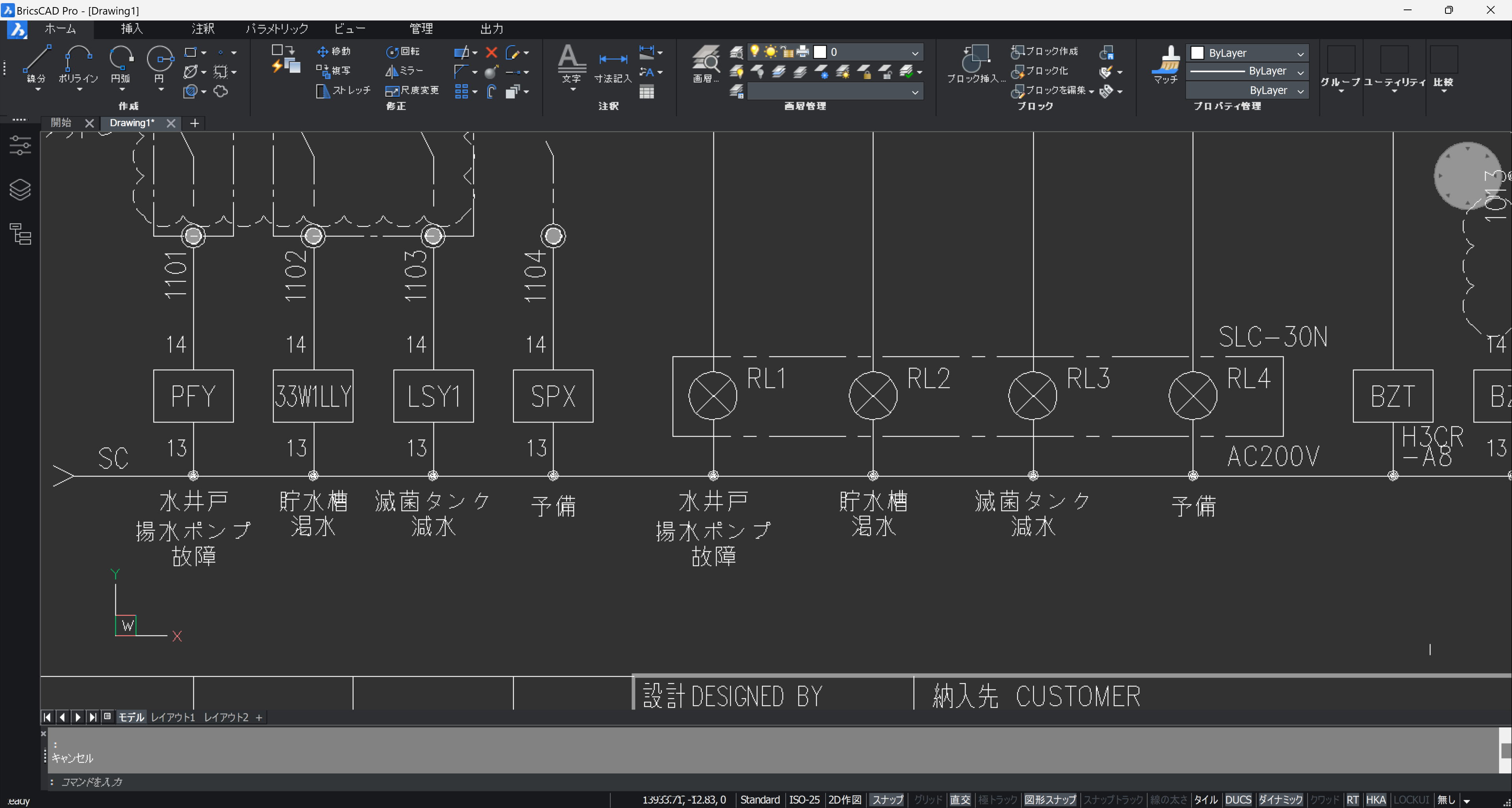
それを PDFIMPORT コマンドでインポートしています。
線分(ポリライン)、円、円弧はそのまま使えますが、SHX フォントは、文字列ではなくポリラインに変換されるため、編集出来なくなっています。
この PDF を 透明テキスト付きの PDF に変換します。結果、OCR 文字と ベクトルデータの無い PDF イメージの PDF が作成されます。
回転している図面は、[高度な設定...] ボタンから 90°毎で回転できます。
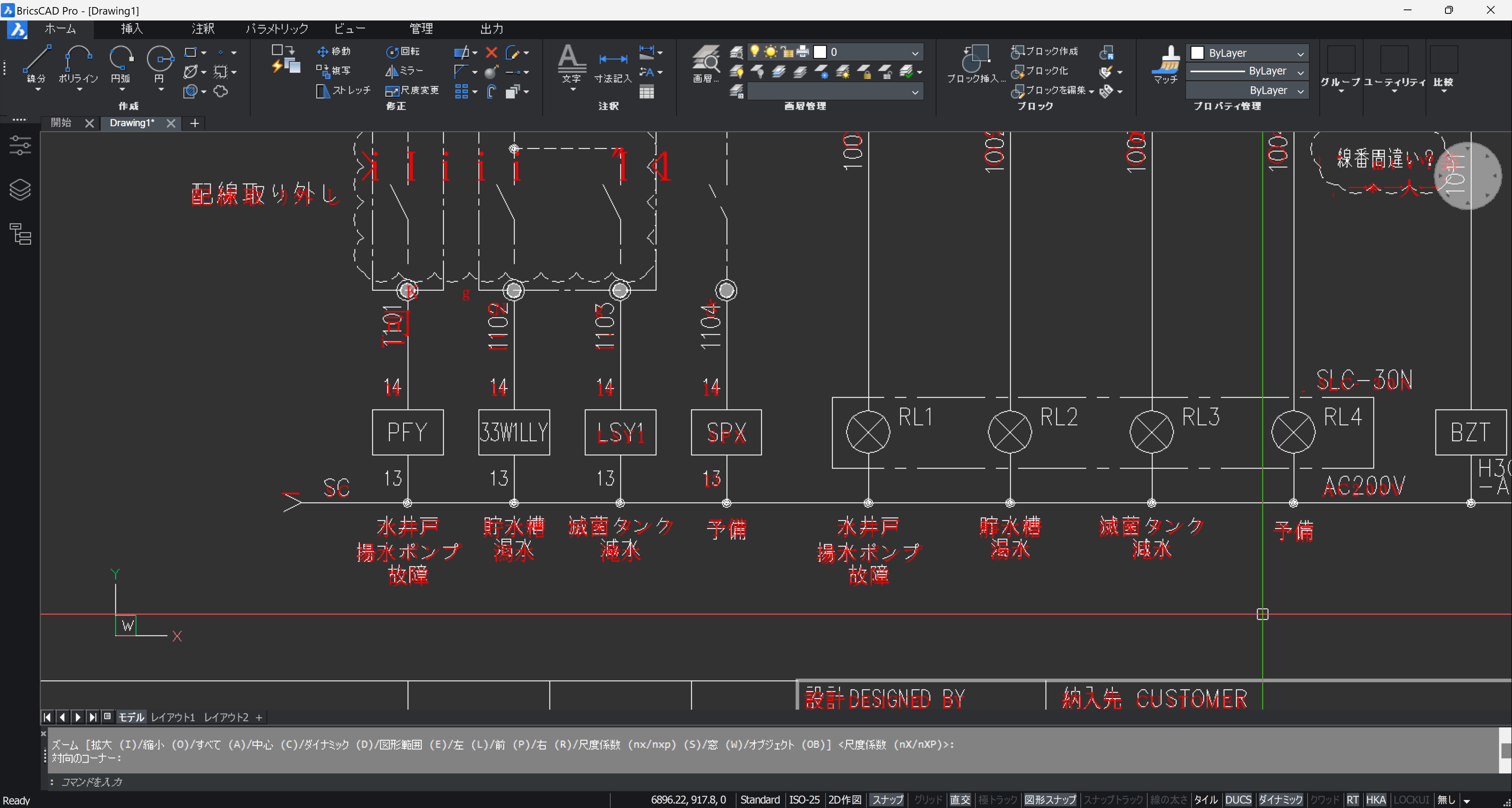
下の画像が、「いきなり PDF to Data」で OCR した PDF を PDFIMPORT した状態です。ベクトルデータは無くなり、文字だけが挿入されます。
元が SHX フォントのため誤認識が多々ありますが、それっぽい文字になっています。
見た目は良い感じですが、実際は1文字ごとに分断されているので、結合しないと文字列として編集できない状態です。
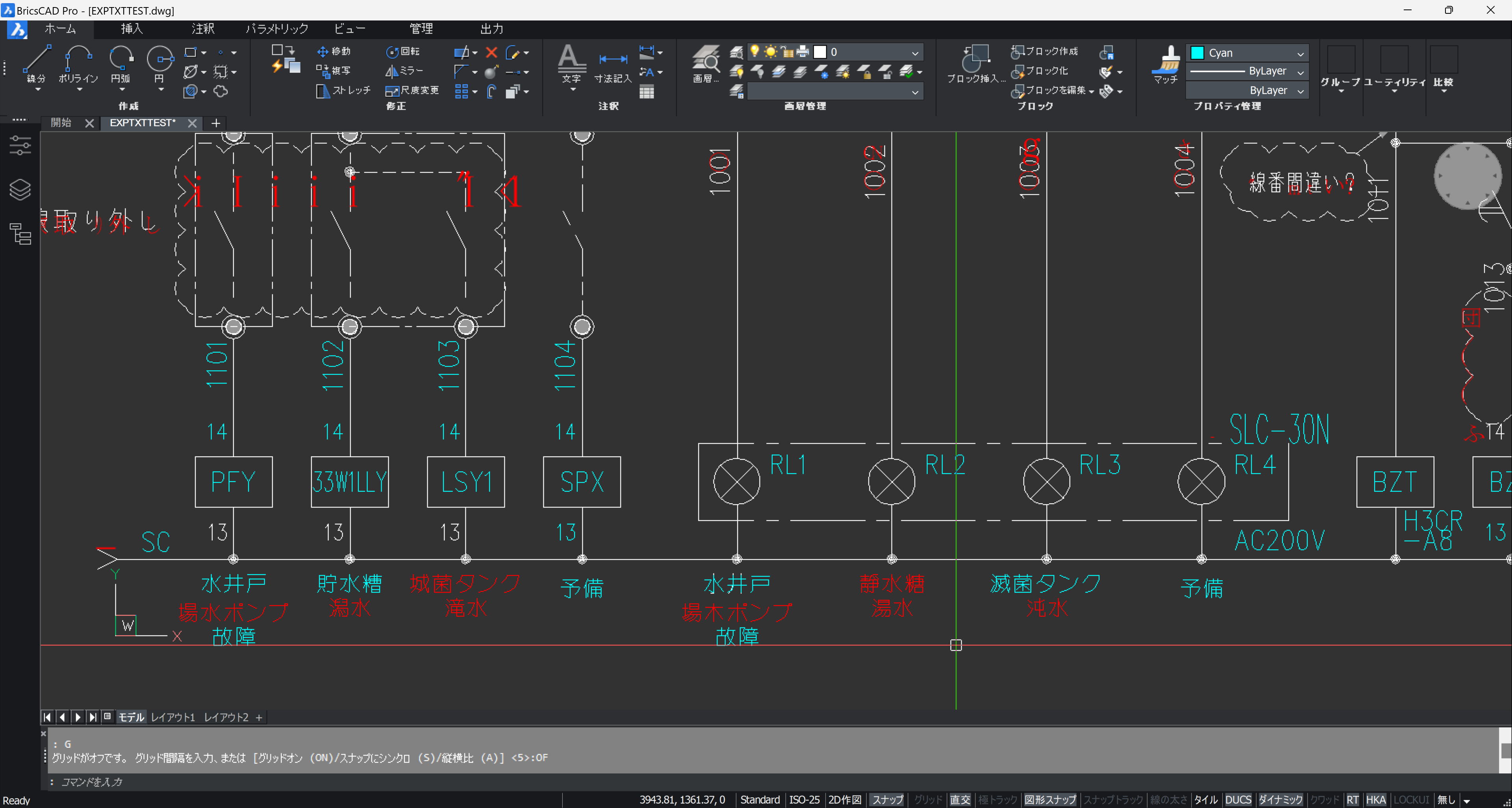
下の画像は、2つの尺度を正確に合わせて重ね合わせた状態で、赤色が OCR 文字です。
文字の位置がほぼ合っていることが分かります。
文字の結合、訂正、文字高さ、幅の再現、認識されていない文字の作成、対象のポリラインの削除。
... 等々を考えると、手間かかるだけでそうメリットがないように思います。
結論としては、使えそうで使えない。かえって邪魔。文字列ごとに確実に TEXT を作成していくのが良いみたいです。