ソースネクスト「読取革命 Ver.17(体験版)」を使ってみました。
元図面は、紙図面をスキャンした PDF で、「読取革命」で傾斜を補正しています。
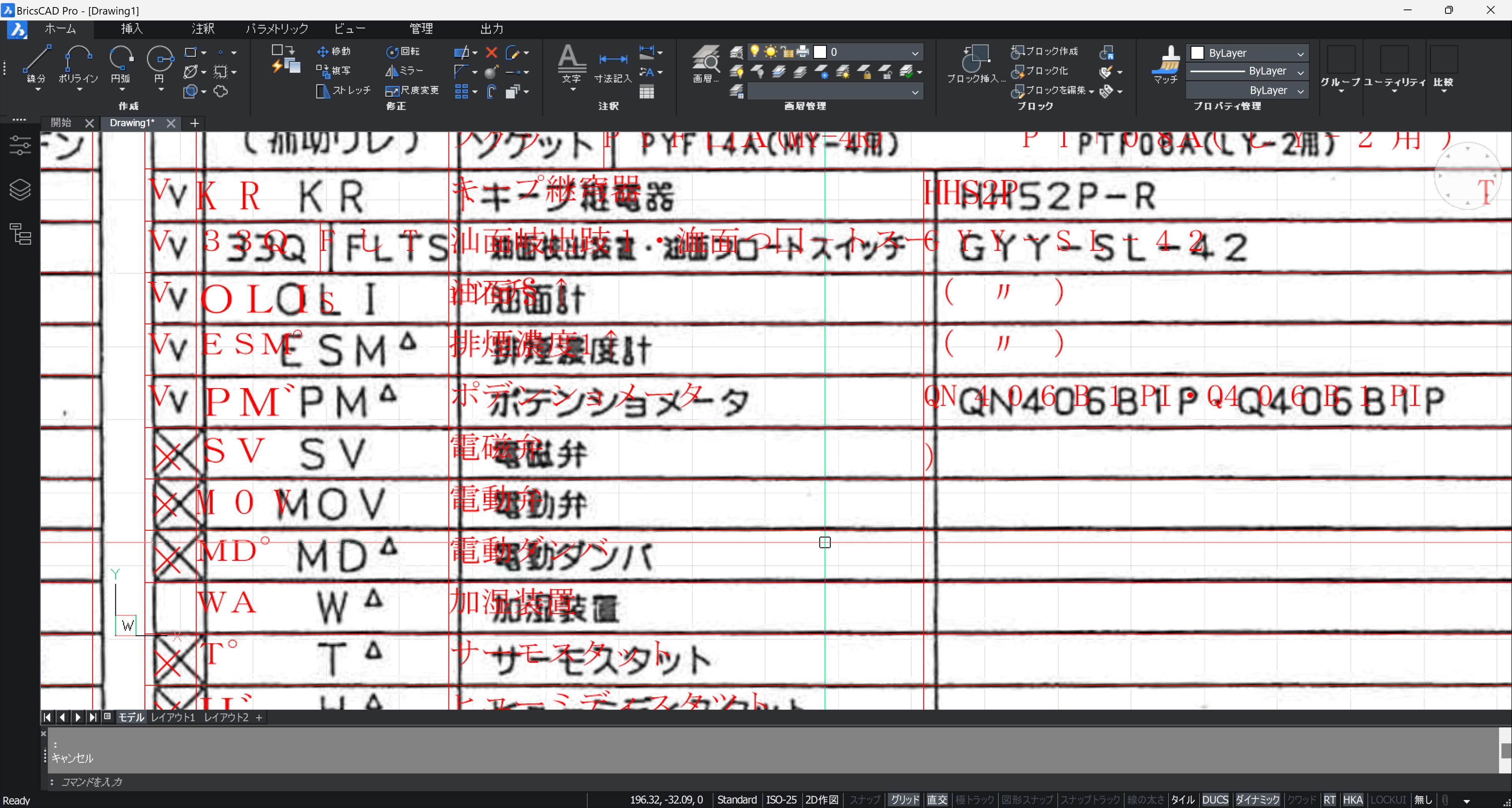
罫線の認識は優秀(な時もある)です。自前でトレースするより速いです。
文字の認識は、罫線内の文字ごとに行うようで、文字の位置ではなく罫線の左上に配置されます。
文字列は、MTEXT になっています。部品リストの作成には使えそうかなとと思います。
CADOCR 3 2024/12/08, 09
ソースネクスト「読取革命 Ver.17(体験版)」を使ってみました。
元図面は、紙図面をスキャンした PDF で、「読取革命」で傾斜を補正しています。
罫線の認識は優秀(な時もある)です。自前でトレースするより速いです。
文字の認識は、罫線内の文字ごとに行うようで、文字の位置ではなく罫線の左上に配置されます。
文字列は、MTEXT になっています。部品リストの作成には使えそうかなとと思います。
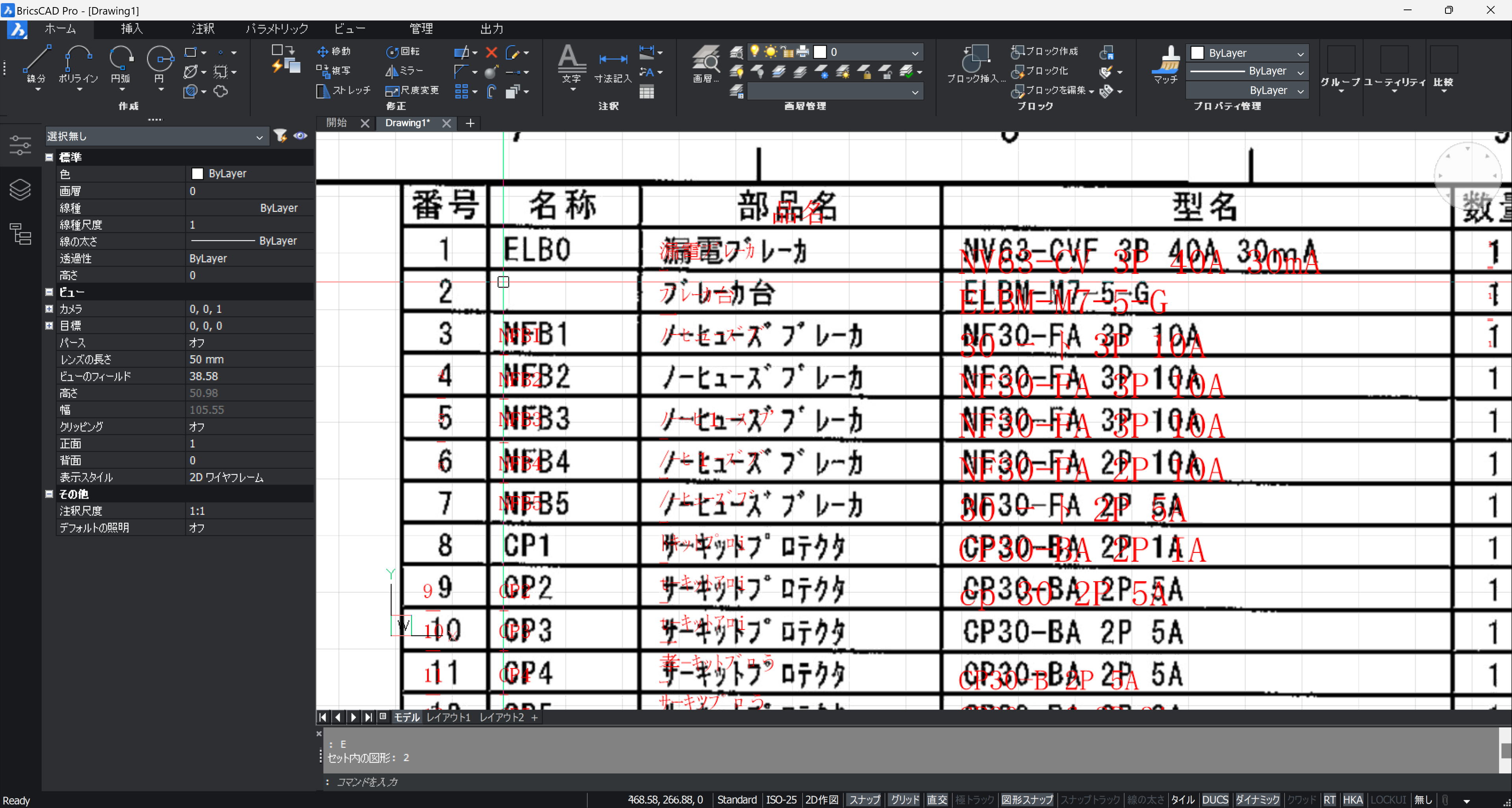
全体はこんな感じ。
用紙の回転、傾斜補正はページごとにしておくと、PDF 全ページが OCR されます。
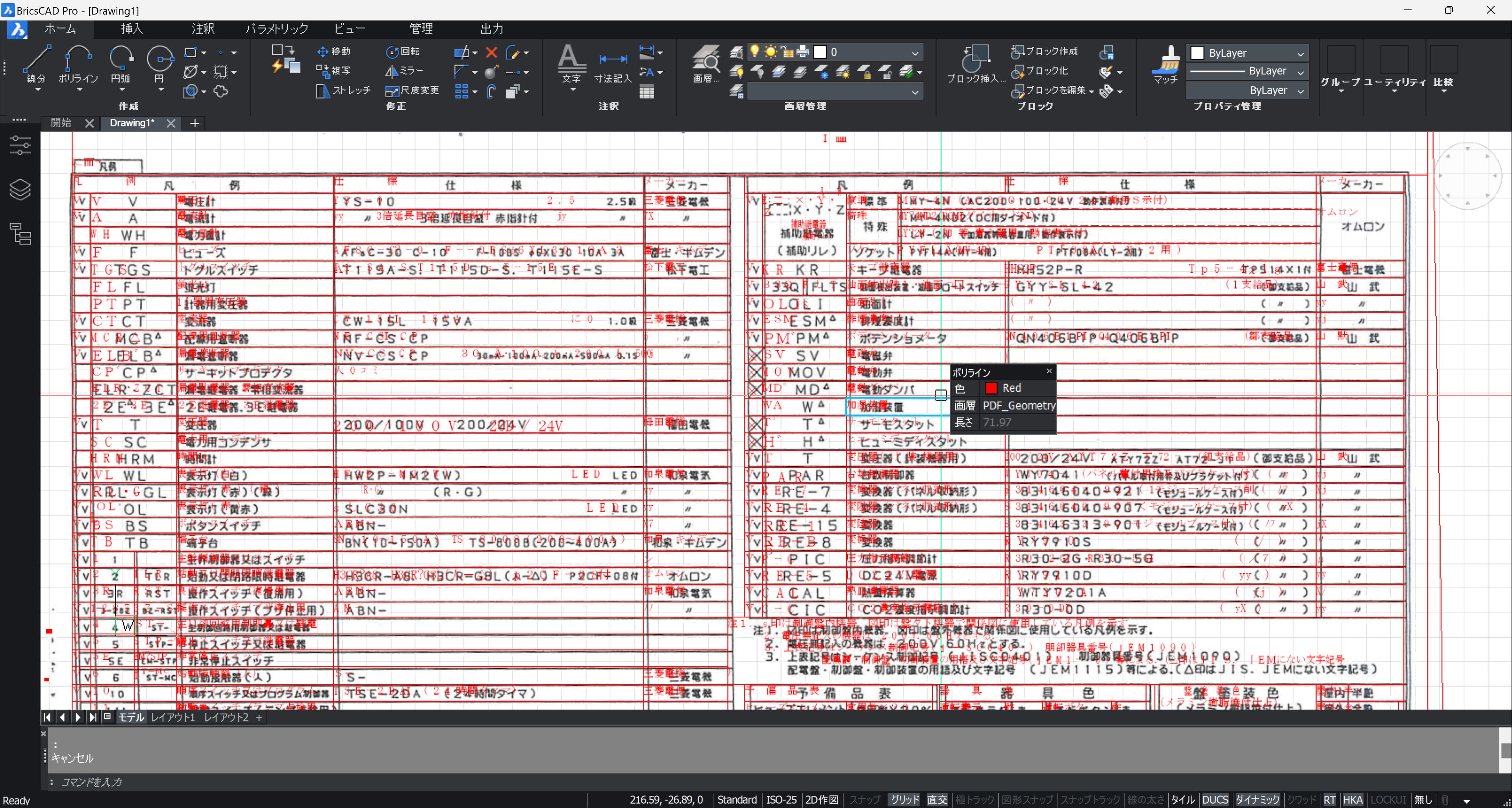
図面の中の一部の罫線は認識されませんでした。
文字も、認識されないところが多々あります。文字が小さすぎるのか、図面内に点在する文字列も認識されませんでした。
レイアウトの認識がうまく出来ていないようです。手動でレイアウトを調整しても良くなりませんでした。
どうも文章の段落を検出しようとしているっぽいです。文章の OCR には適しているのかも知れません。
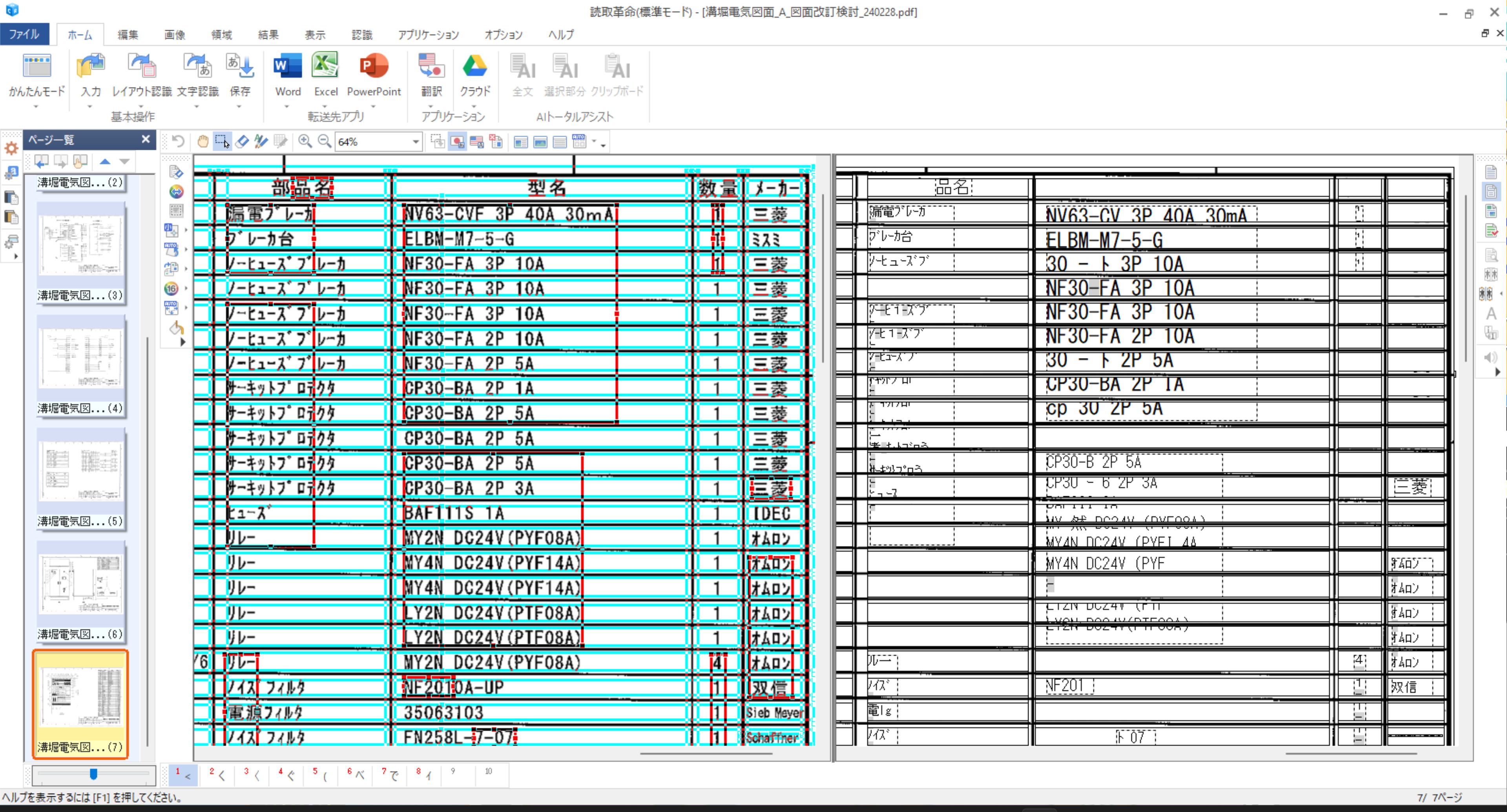
同じ PDF を適度な大きさで画面に表示して、ソースネクストの「瞬間テキスト 3」で OCR すると、こんな感じで認識されます。
「読取革命 Ver.17」では、A3 を A4 に縮小した図面は、認識しにくいのかの知れません。
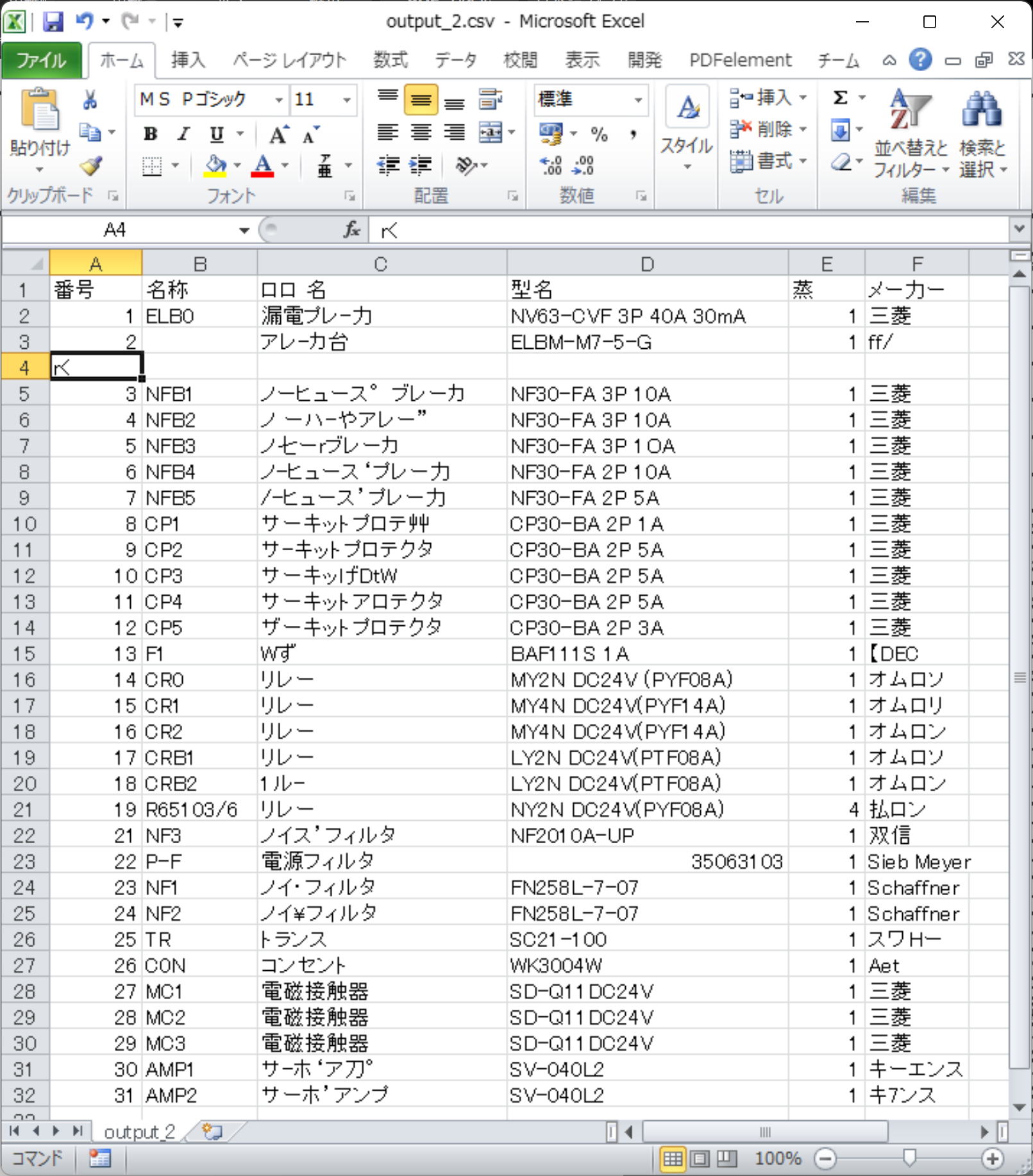
「読取革命 Ver.17」は、「本格読取」の進化版、機能追加版のようでが、「本格読取」が PDF に対応していないだけのことで、OCR 精度はそう変わらない印象です。
OCR 精度で言えば、「PDF to DATA Ver.6」のほうが優秀。画面上の文字に限定されますが、「瞬間テキスト 3」は超優秀です。
「PDF to DATA Ver.6」は、ほぼ同じ位置に文字が作成されるので、CAD 用に使えないこともない。「読取革命 Ver.17」は、文章専用だと思います。
SHXフォントの場合はこんな感じ。傾斜している文字は全滅です。
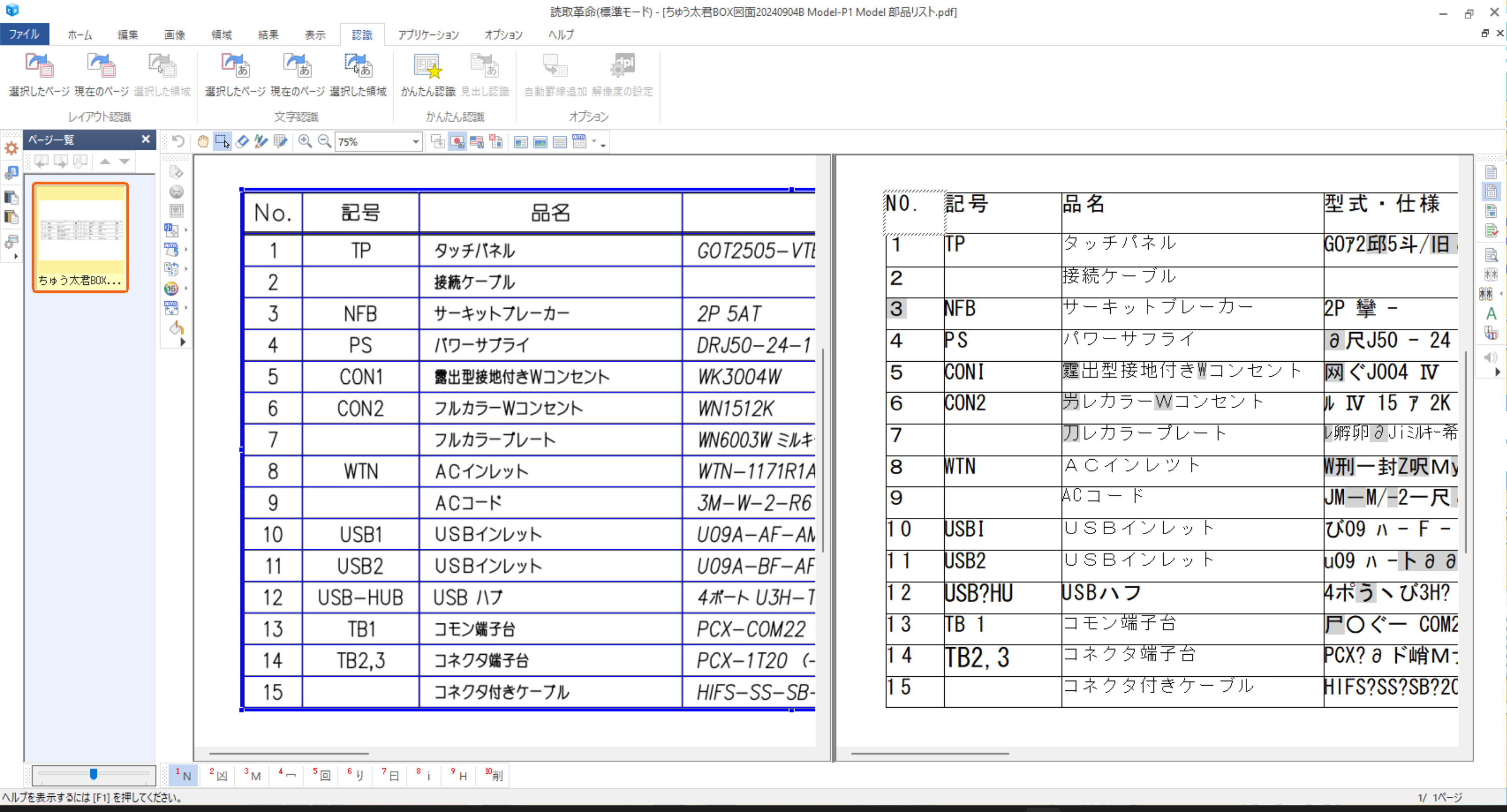
OCR 文字の修正は、「ハイパーチェッカー」が便利です。この機能だけは、欲しいです。
上の段に画像、下の段に OCR された文字が表示されていて、見比べながら修正できます。CAD 上で修正するより速くて間違いも少なくなります。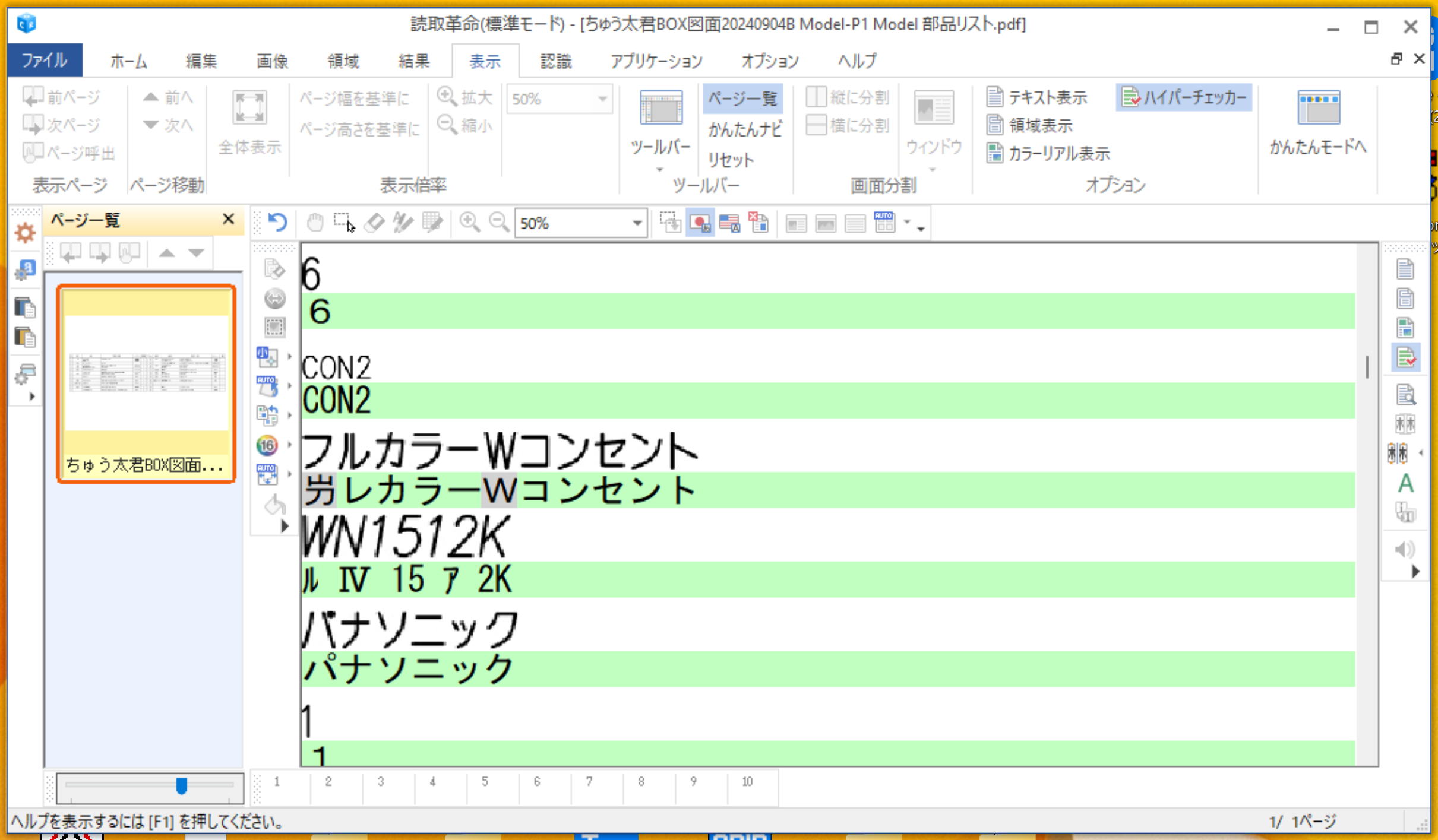
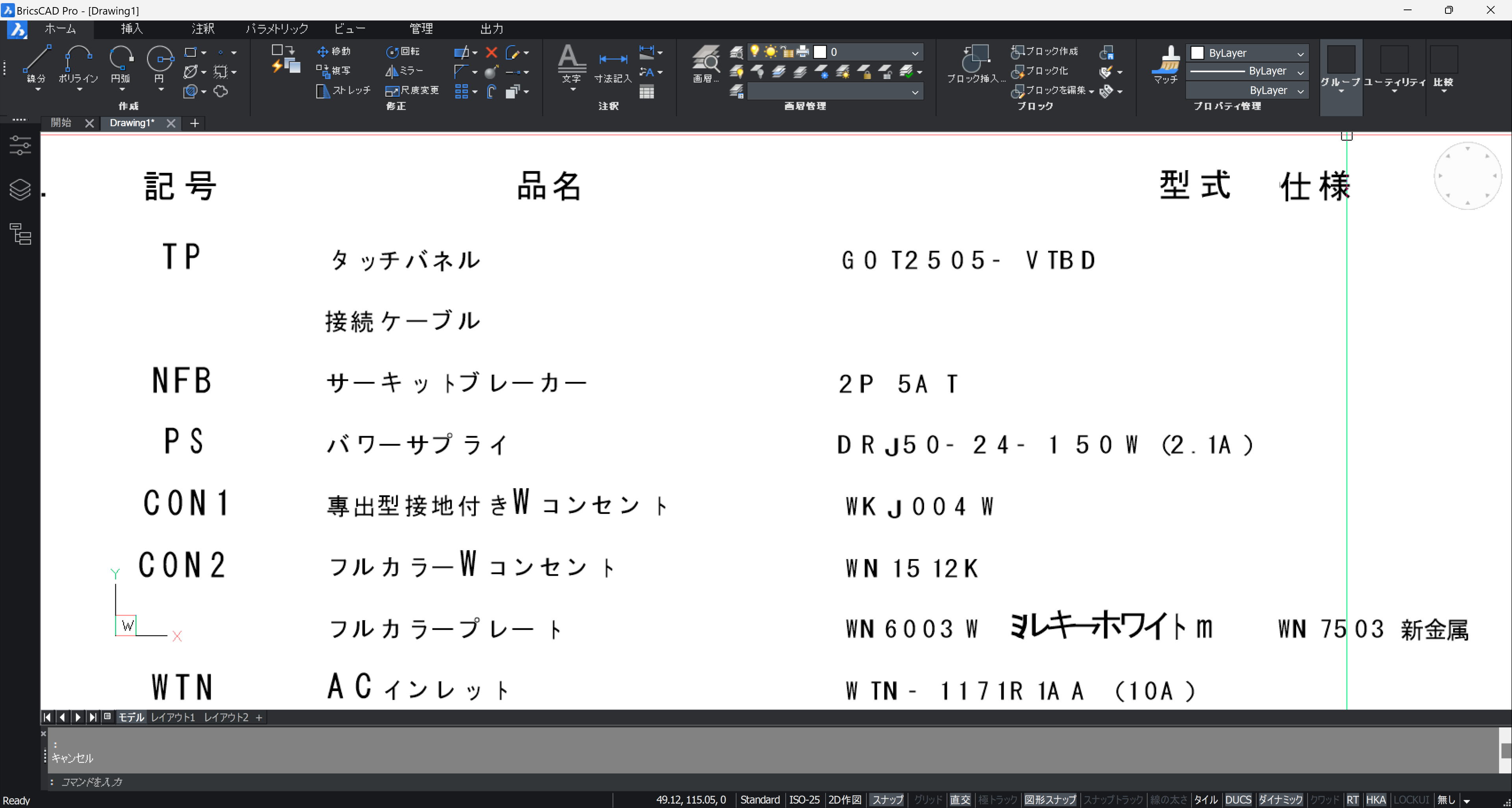
同じ PDF を「PDF to DATA Ver.6」で OCR してみます。
傾斜した SHX フォントも OCR されています。ただし、罫線は無し。文字は1文字ごとに分断されています。
同じ PDF を適度な大きさで画面に表示して、ソースネクストの「瞬間テキスト 3」で OCR すると、こんな感じで認識されます。
他に比べると、超優秀です。
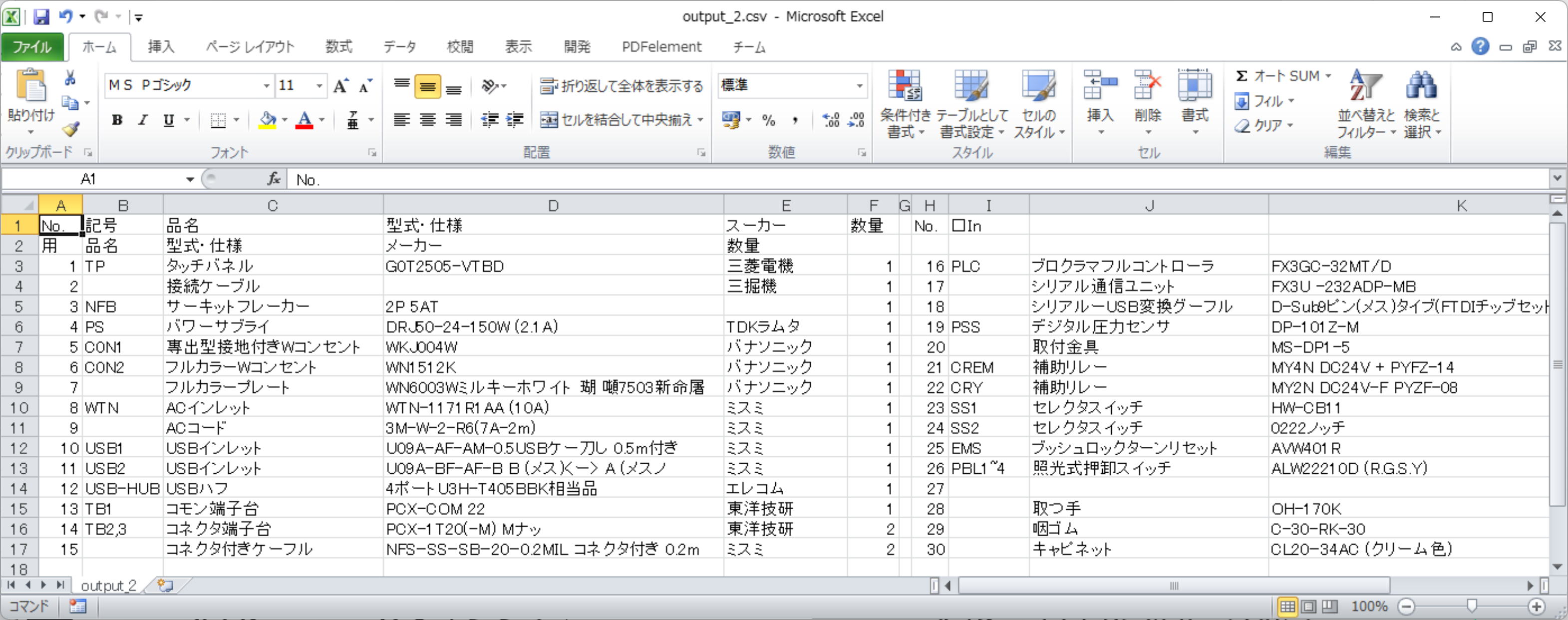
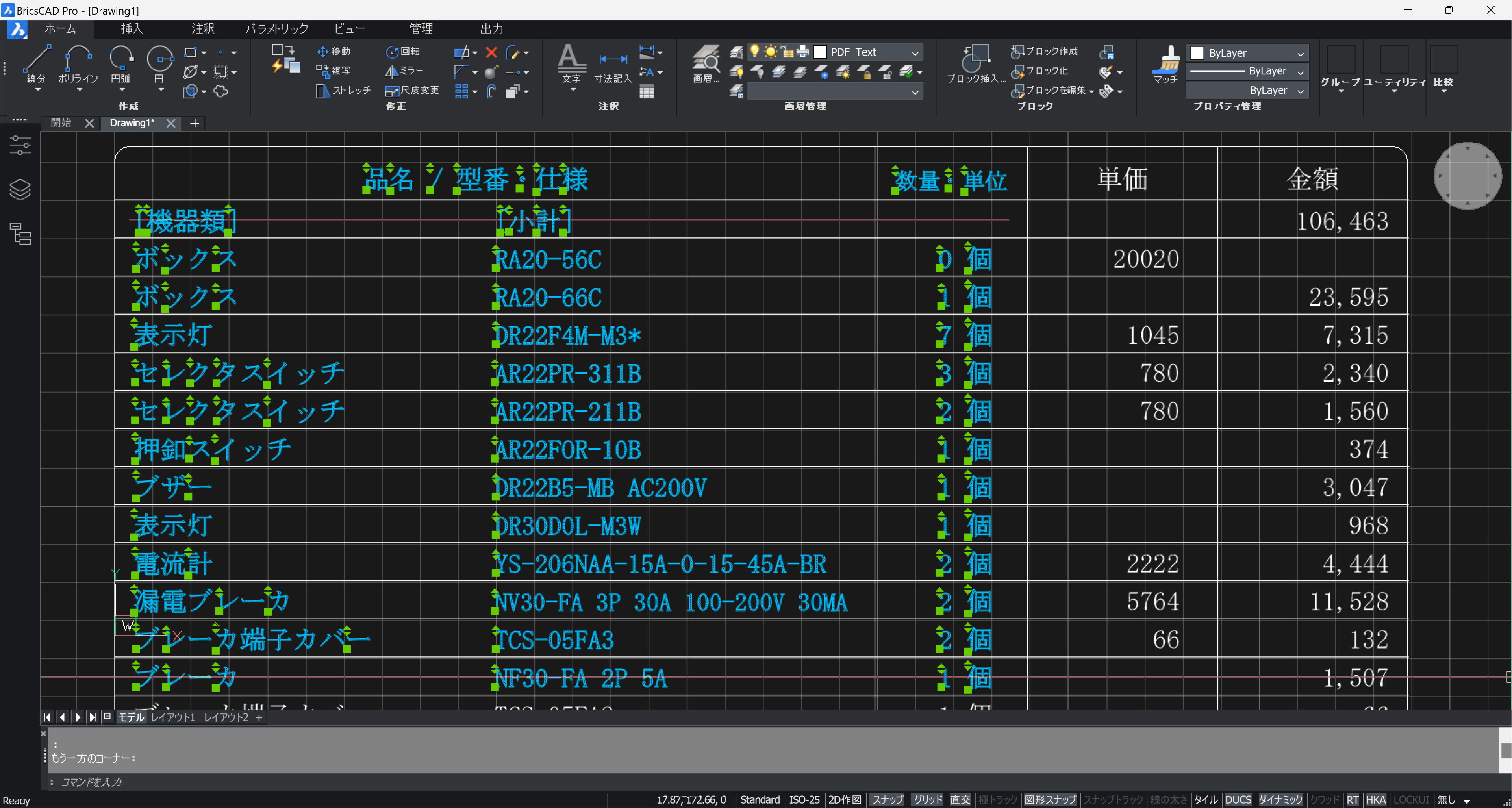
TXPASTE コマンドで CAD 上にペーストすると、こんな感じになります。
部品リストであれば、この方法が簡単、最速です。
表の行高さ、列幅の変更は、TXGSPC。文字位置の変更は、TXGG コマンドが使えます。いずれも BTRIMVX232.lsp に収納されています。
見積書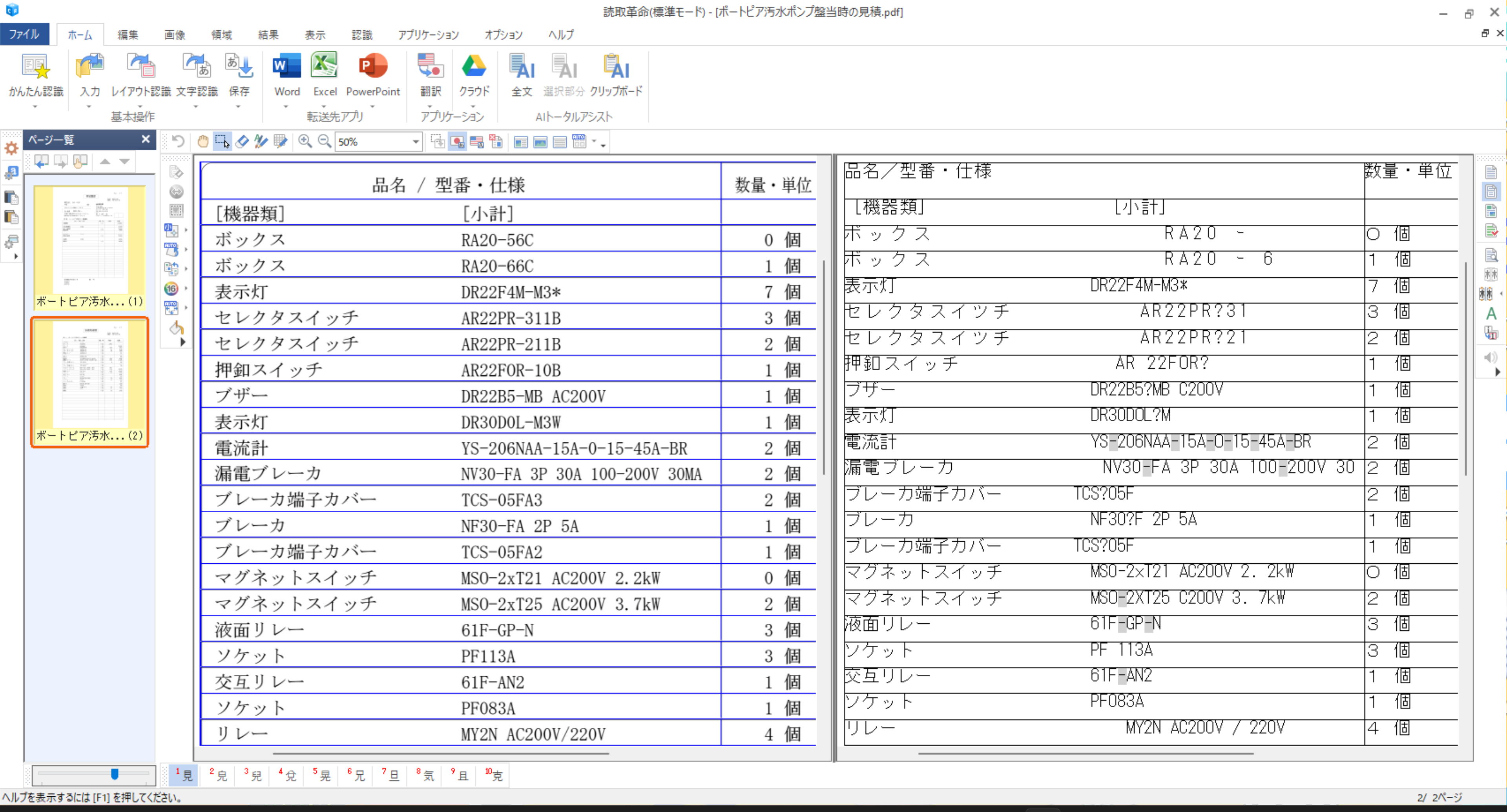
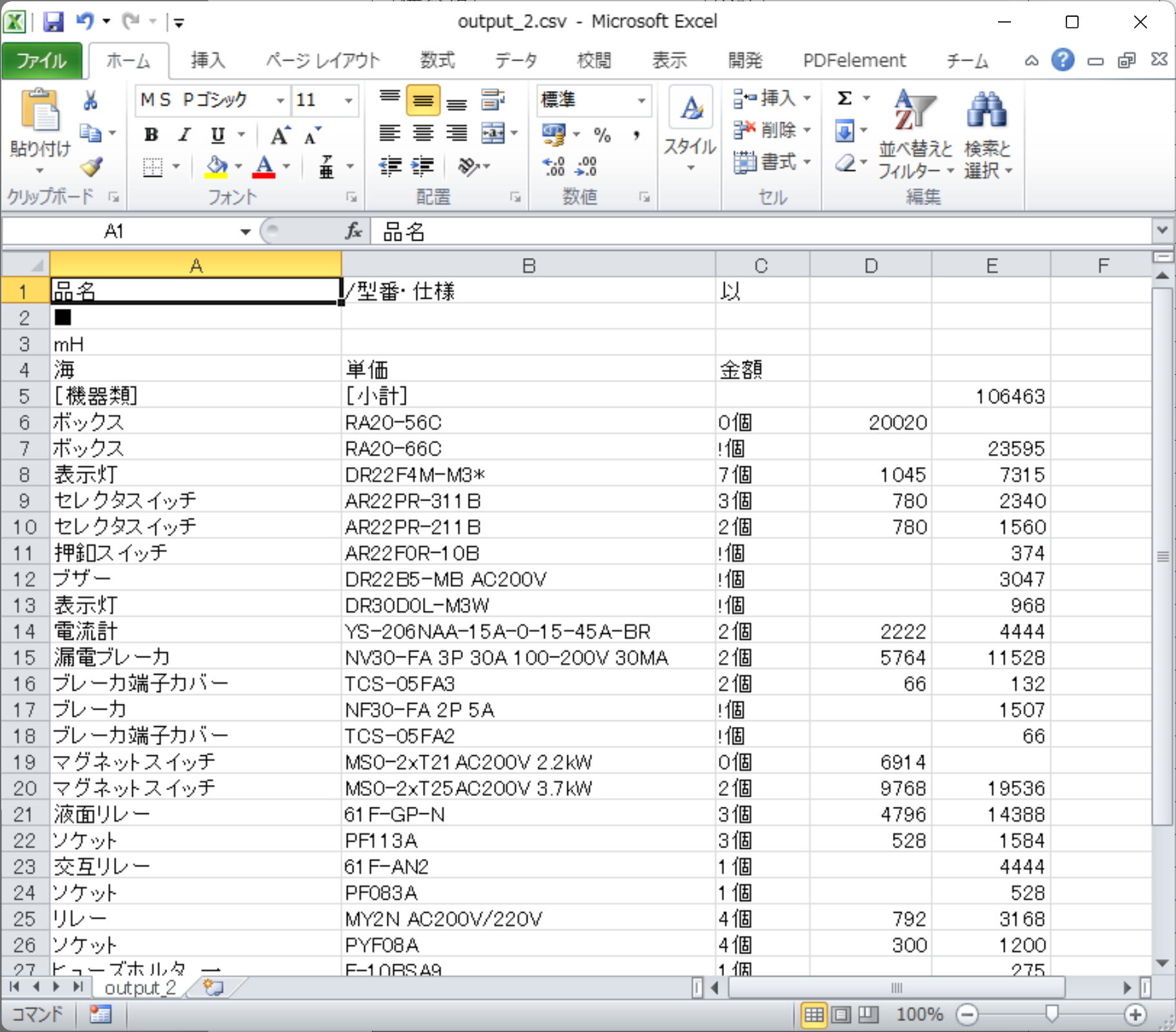
同じ見積書を画面上で 「瞬間テキスト 3」 でOCR。こちらのほうが OCR 精度が良いように思います。
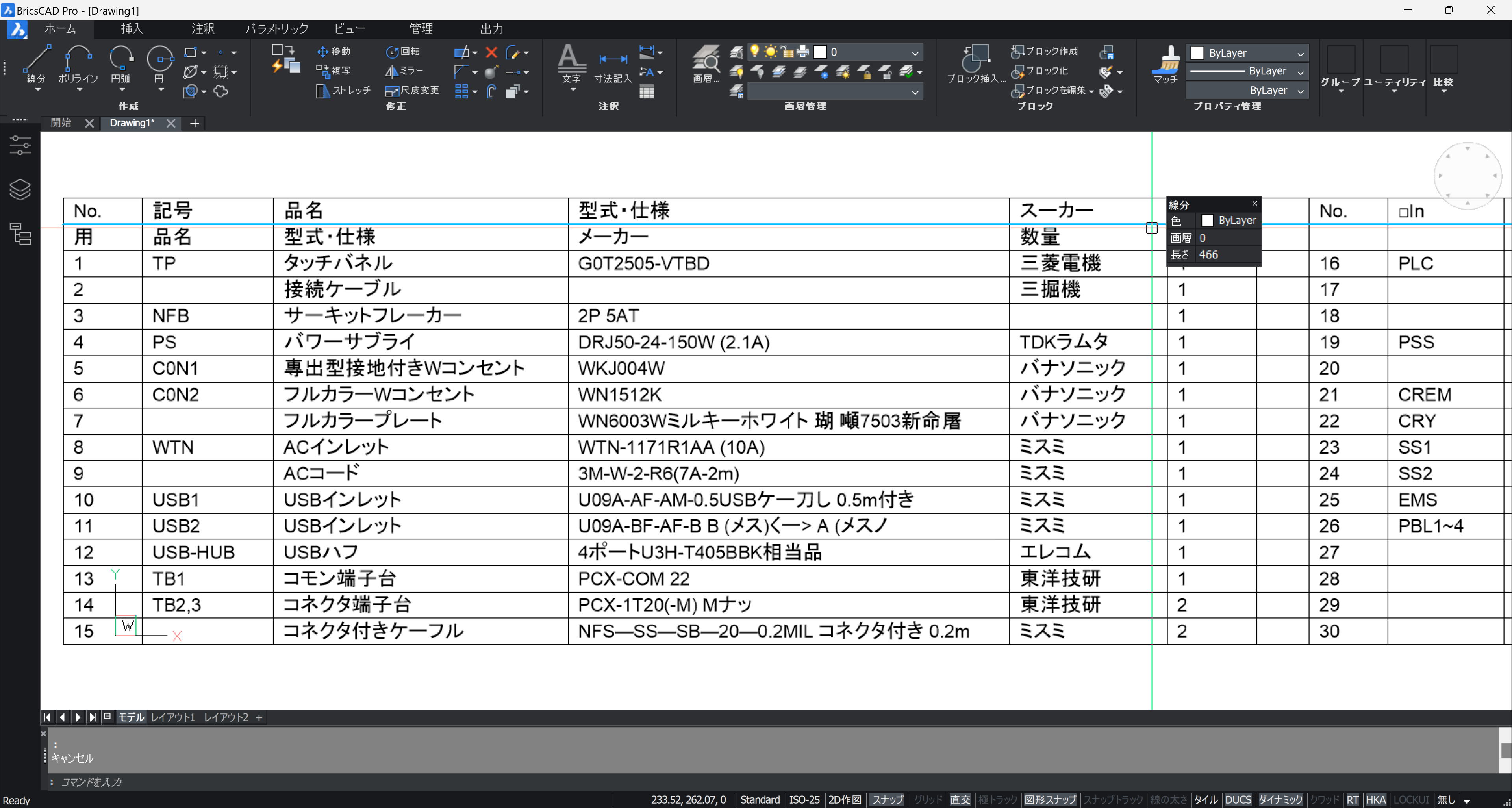
スキャンした PDF でなければ、PDFIMPORT で取り込めます。ただし、文字が分断されていたりします。(BricsCAD v20 の場合)
分断文字の結合には、btrimvx232.lsp の TXLCAT コマンドが使えます。
2024/12/09
f.izawa